
一、人与世界的交互
从远古时代人类文明诞生之日起,人类就在人类就在不断为适应环境、改造环境而艰苦斗争。其中最为基础的前提就是利用感官对外界信息的获取。利用各种感官,人类可以与世界环境进行多种不同的信息交互,例如:
嗅觉:识别各种气味,辨别环境变化和食物、饮水的质量等;
听觉:识别同类的联络信息和天敌等危险信号等
味觉:挑选最适宜的食物
触觉:制作与使用工具时非常重要
另外,最重要的一种自然就是视觉。据统计,在人的各种感官中,视觉占据了超过7成的信息获取量。而且视觉可以使人对环境变化做出最直接的反映。
在文明的发展过程中,人们不满足于仅仅靠着口述记录所看到的影像,而是希望能用更加直观的形式将其记录下来。经过了多年的发展,经过多年的发展,视频已经成为记录和重现信息最为高效的方式,可以在相对很短的时间内传递大量的信息。
视频通过其中每一帧的图像表达信息;
视频包含的音频可提供大量信息;
视频通过图像的运动、场景的变换提供信息;
综上我们可知,视频信息提供了最为接近人的直接体验的信息表示方式。
二、视频信号的表示方法:RGB与YUV
真实世界中的影像与早期的视频处理与传输系统所处理的都是模拟信号。然而为了能适应现代的计算机、网络传输与数字视频处理系统,模拟的视频信号必须转换成数字格式。
RGB颜色空间
目前的显示设备大都是采用了RGB色彩空间,RGB是从颜色的原理来设计定的,它的颜色混合方式就如有红、绿、蓝三盏灯,当它们的光相互叠合的时候,色彩相混,亮度等于两者亮度之总和,即加法混合。
屏幕上的不同颜色,都由这红色,绿色,蓝色三种基本色光按照不同的比例(权重)混合而成的。一组红色绿色蓝色就是一个最小的显示单位。屏幕上的任何一个颜色都可以由一组RGB值来记录和表达。因此这红色绿色蓝色又称为三原色光,用英文表示就是R(red)、G(green)、B(blue)。RGB的所谓“多少”就是指亮度,并使用整数来表示。在用8位表示时,RGB各有256级亮度,用数字量化表示为从0、1、2…直到255。注意虽然数字最高是255,但0也是数值之一,因此共256级。
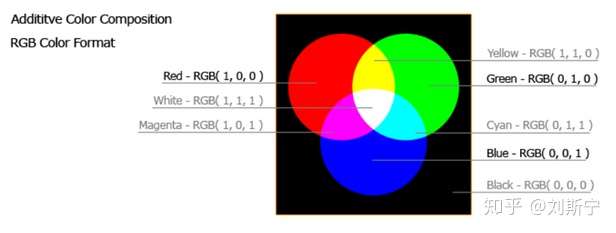
使用这种方式表示彩色图像的方式为RGB颜色空间。RGB颜色空间常用于显示器系统。通过这种形式表示的图像,每个像素的每一个颜色分量用1个字节表示,则可以表示256×256×256种不同的颜色。在常见的图像格式中,如位图(bmp)格式以RGB形式保存数据。
YUV颜色空间
YUV是编码true-color颜色空间(color space)的种类,Y'UV, YUV, YCbCr,YPbPr等专有名词都可以称为YUV,彼此有重叠。
“Y”表示明亮度(Luminance、Luma),“U”和“V”则是色度(Chrominance、Chroma),包含了色调和饱和度。与我们熟知的RGB类似,YUV也是一种颜色编码方法,主要用于电视系统以及模拟视频领域,它将亮度信息(Y)与色彩信息(UV)分离,没有UV信息一样可以显示完整的图像,只不过是黑白的,这样的设计很好地解决了彩色电视机与黑白电视的兼容问题。并且,YUV不像RGB那样要求三个独立的视频信号同时传输,所以用YUV方式传送占用极少的频宽。
在实际的编解码等视频处理的过程中,YUV格式比RGB格式更为常用。在YUV格式中,一个像素由亮度分量和色度分量表示,每一个像素由一个亮度分量Y和两个色度分量U/V组成。亮度分量可以与色度分量一一对应,也可以对色度分量进行采样,即色度分量的总量少于亮度分量。

YCbCr颜色空间
YUV细分的话有Y'UV,YUV,YCbCr,YPbPr等类型,其中YCbCr主要用于数字信号。
YCbCr是被ITU定义在标准ITU-R BT.601(标清SDTV),ITU-R BT.709(高清HDTV),ITU-R BT.2020(超高清)中的一种色彩空间。
YCbCr (SDTV)是在世界数字组织视频标准研制过程中作为ITU – R BT.601 建议的一部分, 其实是YUV经过Gamma的翻版。其中Y与YUV 中的Y含义一致, Cb , Cr 同样都指色彩, 只是在表示方法上不同而已。在YUV 家族中, YCbCr 是在计算机系统中应用最多的成员, 其应用领域很广泛,JPEG、MPEG,H264均采用此格式。
其中,Cr反映了RGB输入信号红色部分与RGB信号亮度值之间的差异,而Cb反映的是RGB输入信号蓝色部分与RGB信号亮度值之间的差异,此即所谓的色差信号。
在视频通信系统中(特别是视频编解码)的“YUV”图像就是YCbCr。在平常的工作交流中,所称的YUV也是YCbCr。以下用YUV指代YCbCr
RGB格式转为YUV格式
Y'= 0.299*R' + 0.587*G' + 0.114*B'
U'= -0.147*R' – 0.289*G' + 0.436*B' = 0.492*(B'- Y')
V'= 0.615*R' – 0.515*G' – 0.100*B' = 0.877*(R'- Y')

YUV格式转为RGB格式
R' = Y' + 1.140*V'
G' = Y' – 0.394*U' – 0.581*V'
B' = Y' + 2.032*U'

RGB格式转为YCbCr格式
按ITU-R BT.601标准。(这个公式应用最广泛)
Y = ( ( 66 * R + 129 * G + 25 * B + 128) >> 8) + 16
Cb = ( ( -38 * R – 74 * G + 112 * B + 128) >> 8) + 128
Cr = ( ( 112 * R – 94 * G – 18 * B + 128) >> 8) + 128

按ITU-R BT.709标准。
Y = 0.183R + 0.614G + 0.062B + 16
Cb = -0.101R – 0.339G + 0.439B + 128
Cr = 0.439R – 0.399G – 0.040B + 128

按JPEG的全范围取值格式
Y = 0.299R + 0.587G + 0.144B + 0
Cb = -0.169R – 0.331G + 0.500B + 128
Cr = 0.500R – 0.419G – 0.081B + 128

YCbCr格式转为RGB格式
R' = 1.164*(Y’-16) + 1.596*(Cr'-128)
G' = 1.164*(Y’-16) – 0.813*(Cr'-128) -0.392*(Cb'-128)
B' = 1.164*(Y’-16) + 2.017*(Cb'-128)

YUV的色度采样
在YUV中之所以采用这样的方式,主要是因为人的感官对亮度信息的敏感度远高于对色度信息。因此相对于其他像素格式,YUV的最大优势是可以适当降低色度分量的采样率,并保证不对图像造成太大影响。而且,使用这种方式还可以兼容黑白和彩色显示设备。对于黑白显示设备,只需要去除色度分量,只显示亮度分量即可。
在YUV中常见的色度采样方式有4:4:4、4:2:2和4:2:0等,如下图所示:


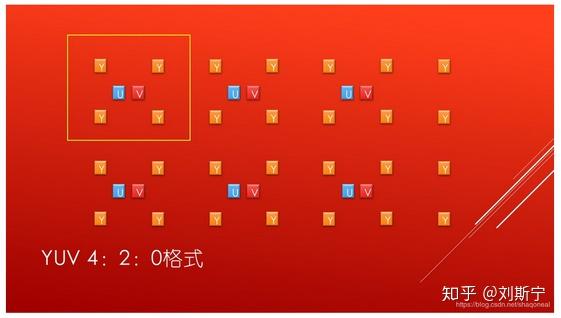
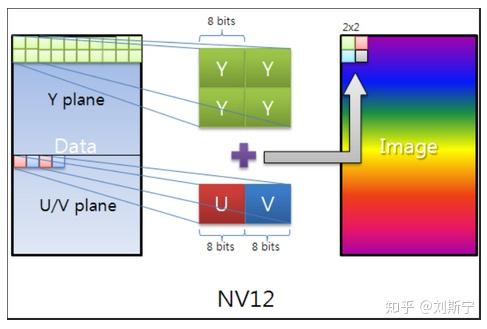
YUV的存储格式
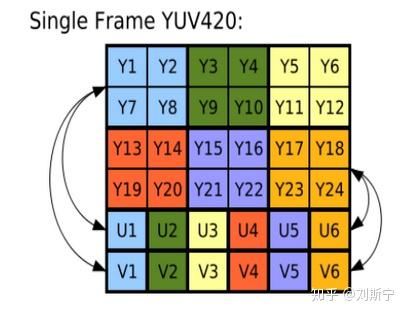
YUV格式有三大类:planar,packed,semi-planar。
对于planar的YUV格式,先连续存储所有像素点的Y,紧接着存储所有像素点的U,随后是所有像素点的V。
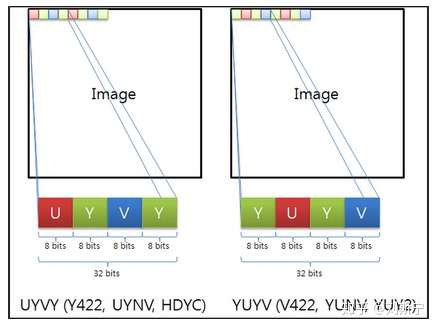
对于packed的YUV格式,每个像素点的Y,U,V是连续交叉存储的。
对于semi-planar的YUV格式,先连续存储所有像素点的Y,紧接着连续交叉存储所有像素点的U,V。
ITU-R Recommendation BT.2020
2012年下半年,国际电信联盟无线电通信部门(ITU-R)颁布了面向新一代超高清UHD(Ultra-high definition)视频制作与显示系统的BT.2020标准,重新定义了电视广播与消费电子领域关于超高清视频显示的各项参数指标,促进4K超高清家用显示设备进一步走向规范化。其中最为关键的是,BT.2020标准指出UHD超高清视频显示系统包括4K与8K两个阶段,其中4K的物理分辨率为3840×2160,而8K则为7680×4320。之所以超高清视频显示系统会有两个阶段,实际上是因为全球各个地区超高清视频显示系统发展差异性所造成的,例如在电视广播领域技术领先的日本就直接发展8K电视广播技术,避免由4K过渡到8K可能出现的技术性障碍。而在世界的其他地区,多数还是以4K技术作为下一代的电视广播发展标准。
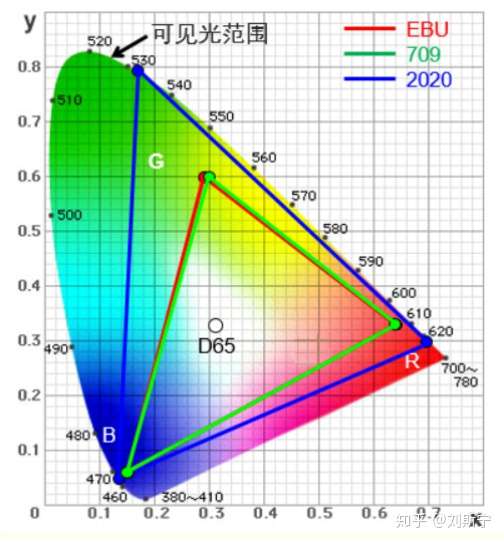
BT.2020标准的重要性是毋庸置疑的,正如BT.709对于高清视频传输与高清显示设备制造方面起到了引导性作用,BT.2020标准同样也深刻地影响着消费领域超高清显示设备的设计与制造,尤其在4K平板电视方面更为突出。例如目前绝大部分的4K平板电视的物理分辨率都是采用BT.2020标准的3840×2160,而不是DCI数字电影标准的4096×2160。但,BT.2020标准绝不仅仅在分辨率方面有所提升,在色彩和刷新频率和信号格式与分析等方面也进行了相关的规定。
4K电视显示标准BT.2020在色彩方面的提升:BT.2020标准相对于BT.709标准,大幅度提升了视频信号的性能规范。例如色彩深度方面,就由BT.709标准的8bit提升至10bit或12bit,其中10bit针对的是4K系统,12bit则针对8K系统。这一提升对于整个影像在色彩层次与过渡方面的增强起到了关键的作用。而色域范围的面积也远远大于BT.709标准,能够显示更加丰富的色彩,只是相对应来说,越广的色域对于显示设备的性能要求就越高,根据目前4K超高清投影机的情况,往往需要采用新一代的激光或LED固态光源的机型才能达到。
三、视频压缩编码
编码这一概念在通信与信息处理领域中广泛使用,其基本原理是将信息按照一定规则使用某种形式的码流表示与传输。常用的需要编码的信息主要有:文字、语音、视频和控制信息等。
1. 为什么需要对视频编码
对于视频数据而言,视频编码的最主要目的是数据压缩。这是因为动态图像的像素形式表示数据量极为巨大,存储空间和传输带宽完全无法满足保存和传输的需求。例如,图像的每个像素的三个颜色分量RGB各需要一个字节表示,那么每一个像素至少需要3字节,分辨率1280×720的图像的大小为2.76M字节。
如果对于同样分辨率的视频,如果帧率为25帧/秒,那么传输所需的码率将达到553Mb/s!如果对于更高清的视频,如1080P、4k、8k视频,其传输码率更是惊人。这样的数据量,无论是存储还是传输都无法承受。因此,对视频数据进行压缩称为了必然之选。
2. 视频信息为什么可以被压缩
视频信息之所以存在大量可以被压缩的空间,是因为其中本身就存在大量的数据冗余。其主要类型有:
时间冗余:视频相邻的两帧之间内容相似,存在运动关系
空间冗余:视频的某一帧内部的相邻像素存在相似性
编码冗余:视频中不同数据出现的概率不同
视觉冗余:观众的视觉系统对视频中不同的部分敏感度不同
针对这些不同类型的冗余信息,在各种视频编码的标准算法中都有不同的技术专门应对,以通过不同的角度提高压缩的比率。
3. 视频编码标准化组织
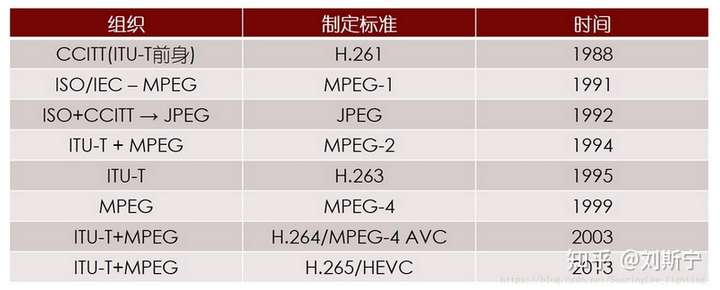
在国际组织的独立和联合开发中,产生了很多重要的视频编解码标准。主要国际组织包括ISO/IEC MPEG、ITU-T、Google、Microsoft、AVS工作组和AOM联盟等。
ITU-T,全称International Telecommunications Union – Telecommunication Standardization Sector,即国际电信联盟——电信标准分局。该组织下设的VECG(Video Coding Experts Group)主要负责面向实时通信领域的标准制定,主要制定了H.261/H263/H263+/H263++等标准。
ISO,全称International Standards Organization,即国际标准化组织。该组织下属的MPEG(Motion Picture Experts Group),即移动图像专家组主要负责面向视频存储、广播电视、网络传输的视频标准,主要制定了MPEG-1/MPEG-4等。
实际上,真正在业界产生较强影响力的标准均是由两个组织合作产生的。比如MPEG-2、H.264/AVC和H.265/HEVC等。
主要标准包括:JPEG、MJPEG、JPEG2000、H.261、MPEG-1、H.262/MPEG-2、H.263、MPEG-4 (Part2/ASP)、H.264/MPEG-4 (Part10/AVC)、H.265/MPEG-H (Part2/HEVC)、H.266/VVC、VP8/VP9、AV1、AVS1/AVS2、SVAC1/SVAC2等。
不同标准组织制定的视频编码标准的发展如下图所示:
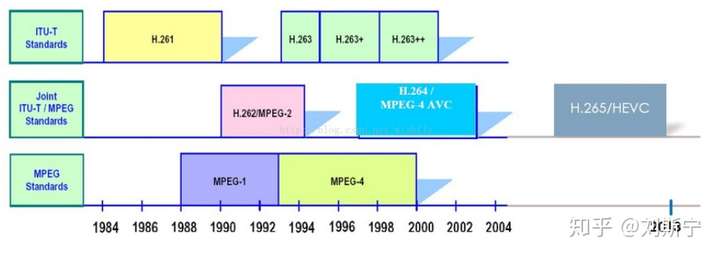
4、主要视频编码标准介绍
4.1、JPEG
JPEG 是Joint Photographic Experts Group(联合图像专家小组)的缩写,是第一个国际图像压缩标准。JPEG图像压缩算法能够在提供良好的压缩性能的同时,具有比较好的重建质量,被广泛应用于图像、视频处理领域。
4.2、MJPEG
M-JPEG(Motion- Join Photographic Experts Group)技术即运动静止图像(或逐帧)压缩技术,广泛应用于非线性编辑领域可精确到帧编辑和多层图像处理,把运动的视频序列作为连续的静止图像来处理,这种压缩方式单独完整地压缩每一帧,在编辑过程中可随机存储每一帧,可进行精确到帧的编辑,此外M-JPEG的压缩和解压缩是对称的,可由相同的硬件和软件实现。但M-JPEG只对帧内的空间冗余进行压缩。不对帧间的时间冗余进行压缩,故压缩效率不高。采用M-JPEG数字压缩格式,当压缩比7:1时,可提供相当于Betecam SP质量图像的节目。
JPEG标准所根据的算法是基于DCT(离散余弦变换)和可变长编码。JPEG的关键技术有变换编码、量化、差分编码、运动补偿、霍夫曼编码和游程编码等
M-JPEG的优点是:可以很容易做到精确到帧的编辑、设备比较成熟。缺点是压缩效率不高。
此外,M-JPEG这种压缩方式并不是一个完全统一的压缩标准,不同厂家的编解码器和存储方式并没有统一的规定格式。这也就是说,每个型号的视频服务器或编码板有自己的M-JPEG版本,所以在服务器之间的数据传输、非线性制作网络向服务器的数据传输都根本是不可能的。
4.3、JPEG2000
JPEG 2000 (JP2) is an image compression standard and coding system. It was created by the Joint Photographic Experts Group committee in 2000 with the intention of superseding their original discrete cosine transform-based JPEG standard (created in 1992) with a newly designed, wavelet-based method. The standardized filename extension is .jp2 for ISO/IEC 15444-1 conforming files and .jpx for the extended part-2 specifications, published as ISO/IEC 15444-2. The registered MIME types are defined in RFC 3745. For ISO/IEC 15444-1 it is image/jp2.
4.4、H.261
H.261视频编码标准诞生于1988年,可谓是视频压缩编码发展的第一个里程碑。因为从H.261开始,视频编码方法采用了沿用至今的基于波形的混合编码方法。H.261标准主要目标是用于视频会议和可视电话等高实时性、低码率的视频图像传输场合。
在H.261标准产生的时代,由于各国的电视制式不一致,因此不能直接互通。为了解决数据源格式不兼容的问题,H.261定义了一种公共中间格式CIF(Common Intermediate Format)。编码的目标格式首选转换为CIF格式进行编码和传输,接收端进行解码后再转换为各自的格式。H.261规定的CIF格式视频的亮度分辨率为352×288,QCIF格式的亮度分辨率为176×144。
H.261信源编码所采用的技术:
帧内编码/帧间编码判定:根据帧与帧之间的相关性判定——相关性高使用帧间编码,相关性低使用帧内编码。
帧内编码:对于帧内编码帧,直接使用DCT编码8×8的像素块。
帧间编码/运动估计:使用以宏块为基础的运动补偿预测编码;当前宏块从参考帧中查找最佳匹配宏块,并计算其相对偏移量(Vx, Vy)作为运动矢量;编码器使用DCT、量化编码当前宏块和预测宏块的残差信号;帧间编码/运动估计:使用以宏块为基础的运动补偿预测编码;当前宏块从参考帧中查找最佳匹配宏块,并计算其相对偏移量(Vx, Vy)作为运动矢量;编码器使用DCT、量化编码当前宏块和预测宏块的残差信号;
环路滤波器:实际上是一个数字低通滤波器,滤除不必要的高频信息,以消除方块效应;环路滤波器:实际上是一个数字低通滤波器,滤除不必要的高频信息,以消除方块效应;
4.5、MPEG-1
MPEG-1标准于1993年8月公布,用于传输1.5Mbps数据传输率的数字存储媒体运动图像及其伴音的编码。该标准包括五个部分:
第一部分说明了如何根据第二部分(视频)以及第三部分(音频)的规定,对音频和视频进行复合编码。第四部分说明了检验解码器或编码器的输出比特流符合前三部分规定的过程。第五部分是一个用完整的C语言实现的编码和解码器。
该标准从颁布的那一刻起,MPEG-1取得一连串的成功,如VCD和MP3的大量使用,Windows95以后的版本都带有一个MPEG-1软件解码器,可携式MPEG-1摄像机等等。
4.6、MPEG-2/H.262
MPEG组织于1994年推出MPEG-2压缩标准,以实现视/音频服务与应用互操作的可能性。 MPEG-2标准是针对标准数字电视和高清晰度电视在各种应用下的压缩方案和系统层的详细规定,编码码率从每秒3兆比特~100兆比特,标准的正式规范在ISO/IEC13818中。MPEG-2不是MPEG-1的简单升级,MPEG-2在系统和传送方面作了更加详细的规定和进一步的完善。MPEG-2特别适用于广播级的数字电视的编码和传送,被认定为SDTV和HDTV的编码标准。
MPEG-2图像压缩的原理是利用了图像中的两种特性:空间相关性和时间相关性。这两种相关性使得图像中存在大量的冗余信息。如果我们能将这些冗余信息去除,只保留少量非相关信息进行传输,就可以大大节省传输频带。而接收机利用这些非相关信息,按照一定的解码算法,可以在保证一定的图像质量的前提下恢复原始图像。一个好的压缩编码方案就是能够最大限度地去除图像中的冗余信息。
MPEG-2的编码图像被分为三类,分别称为I帧,P帧和B帧。 I帧图像采用帧内编码方式,即只利用了单帧图像内的空间相关性,而没有利用时间相关性。P帧和B帧图像采用帧间编码方式,即同时利用了空间和时间上的相关性。P帧图像只采用前向时间预测,可以提高压缩效率和图像质量。P帧图像中可以包含帧内编码的部分,即P帧中的每一个宏块可以是前向预测,也可以是帧内编码。B帧图像采用双向时间预测,可以大大提高压缩倍数。
MPEG-2的编码码流分为六个层次。为更好地表示编码数据,MPEG-2用句法规定了一个层次性结构。它分为六层,自上到下分别是:图像序列层、图像组(GOP)、图像、宏块条、宏块、块。
4.7、H.263
H.263是国际电联ITU-T的一个标准草案,是为低码流通信而设计的。但实际上这个标准可用在很宽的码流范围,而非只用于低码流应用,它在许多应用中可以认为被用于取代H.261。H.263的编码算法与H.261一样,但做了一些改善和改变,以提高性能和纠错能力。.263标准在低码率下能够提供比H.261更好的图像效果,两者的区别有:(1)H.263的运动补偿使用半象素精度,而H.261则用全象素精度和循环滤波;(2)数据流层次结构的某些部分在H.263中是可选的,使得编解码可以配置成更低的数据率或更好的纠错能力;(3)H.263包含四个可协商的选项以改善性能;(4)H.263采用无限制的运动向量以及基于语法的算术编码;(5)采用事先预测和与MPEG中的P-B帧一样的帧预测方法;(6)H.263支持5种分辨率,即除了支持H.261中所支持的QCIF和CIF外,还支持SQCIF、4CIF和16CIF,SQCIF相当于QCIF一半的分辨率,而4CIF和16CIF分别为CIF的4倍和16倍。
1998年IUT-T推出的H.263+是H.263建议的第2版,它提供了12个新的可协商模式和其他特征,进一步提高了压缩编码性能。如H.263只有5种视频源格式,H.263+允许使用更多的源格式,图像时钟频率也有多种选择,拓宽应用范围;另一重要的改进是可扩展性,它允许多显示率、多速率及多分辨率,增强了视频信息在易误码、易丢包异构网络环境下的传输。另外,H.263+对H.263中的不受限运动矢量模式进行了改进,加上12个新增的可选模式,不仅提高了编码性能,而且增强了应用的灵活性。H.263已经基本上取代了H.261。
4.8、MPEG-4 (Part2/ASP)
运动图像专家组MPEG 于1999年2月正式公布了MPEG-4(ISO/IEC14496)标准第一版本。同年年底MPEG-4第二版亦告底定,且于2000年年初正式成为国际标准。
MPEG-4与MPEG-1和MPEG-2有很大的不同。MPEG-4不只是具体压缩算法,它是针对数字电视、交互式绘图应用(影音合成内容)、交互式多媒体(WWW、资料撷取与分散)等整合及压缩技术的需求而制定的国际标准。MPEG-4标准将众多的多媒体应用集成于一个完整的框架内,旨在为多媒体通信及应用环境提供标准的算法及工具,从而建立起一种能被多媒体传输、存储、检索等应用领域普遍采用的统一数据格式。
4.9、H.264/MPEG4 (Part10 AVC)
H.264是由ISO/IEC与ITU-T组成的联合视频组(JVT)制定的新一代视频压缩编码标准。在ISO/IEC中该标准命名为AVC (Advanced Video Coding),作为MPEG-4标准的第10个选项;在ITU-T中正式命名为H.264标准。
4.10、H.265/HEVC
H.265是ITU-T VCEG 继H.264之后所制定的新的视频编码标准。H.265标准围绕着现有的视频编码标准H.264,保留原来的某些技术,同时对一些相关的技术加以改进。新技术使用先进的技术用以改善码流、编码质量、延时和算法复杂度之间的关系,达到最优化设置。具体的研究内容包括:提高压缩效率、提高鲁棒性和错误恢复能力、减少实时的时延、减少信道获取时间和随机接入时延、降低复杂度等。H264由于算法优化,可以低于1Mbps的速度实现标清数字图像传送;H265则可以实现利用1~2Mbps的传输速度传送720P(分辨率1280*720)普通高清音视频传送。
4.11、VP8/VP9
https://en.wikipedia.org/wiki/VP8
4.12、AV1
AV1(AOMedia Video Codec 1.0):
相关网址:
http://audiovisualone.com : AV1公司网站
http://audio-video1.com :主要面向家庭提供视音频应用的供应商
http://www.ctolib.com/learndromoreira-digital video introdution.html :相关学习资料
https://xiph.org/daala :Xiph(Mozilla基金会)的视频压缩技术,即Daala(达拉)
http://aomedia.org : 开放媒体联盟官网,主要由一些硬件制造商共同建立,是发布AV1的主要组织
http://aomanalyzer.org/ : AV1编解码器对应的码流分析工具网站
AV1背景:
2015年年初,Google正致力于VP10的研究,Xiph在继续Daala视频压缩技术的研究,Cisco开源了免版税的视频编解码器,即雷神(Thor)。 之后,MPEG-LA公司首次宣布H265的使用年费(是使用H264的8倍多)。由于H265使用年费太高,一些硬件制造商(Amozon、Cisco、Google、Intel、Microsoft、Mozilla、Netflix)于2015年9月联合成立了“开放媒体联盟”,其中内容的发布由Google、Netflix和Amozon负责,网站的维护由Google和Mozilla负责。2016年4月5日,AMD、ARM和NVIDIA也加入了该联盟,这些加入联盟的公司都有一个共同的目标,即开发出一个免版税的视频编解码器,此时AV1顺势而起。
AV1简介:
AV1是一种免版税、开源的新视频编码标准,集成Daala、Thor和VPx部分最优秀的编码思想,由开放媒体联盟(AOMedia)发布,目前第一版Version0.1.0已经在2016年4月7日发布。AV1现阶段的主要目标是在编解码复杂度合理增加的前提下,编码性能高于VP9/HEVC的50%。
AOMedia声称,预计在2016年年底至2017年3月最终确定AV1码流相关信息,并于2018年3月首次在硬件上支持。需要说明的是,AV1与以往视频编码标准较大的区别之一是更加偏向于硬件编解码的支持,这也是AV1发起者(大多数为硬件设备制造厂商)的个人利益角度所考虑的。
AV1资源下载:
AV1源码下载地址:https://aomedia.googlesource.com/aom
AV1测试视频序列:http://media.xipha.org/video/derf/
AV1码流分析工具源码:https://github.com/mbebenita/aomanalyzer
AV1码流分析工具:https://people.xiph.org/~mbebenita/analyzer/
4.13、AVS1/AVS2
AVS1标准是中国自主研发的音视频编解码标准,主要用于国内卫星电视的压缩传输,其压缩率相较于H.264要低一些,在使用范围和推广上也不如H.264。
4.14、SVAC1/SVAC2
SVAC(Surveillance Video and Audio Coding),安全防范监控音视频编解码技术,该技术标准是有中星微和公安一所针对视频监控应用提出的音视频编码标准,该标准2010年12月23日发布,于2011年5月1日开始实施。
SVAC标准的主要技术特点有以下几点:
1)高精度,支持8bit~10bit;
2)支持帧内4×4预测与变换量化,支持自适应帧-场编码(AFF)和CABAC等技术。
3)支持ROI变质量编码和SVC可伸缩编码。
4)支持监控专用信息,数据安全保护和加密认证。
4.15、H.266/VVC
JVET was founded as the Joint Video Exploration Team (on Future Video coding) of ITU-T VCEG and ISO/IEC MPEG in October 2015. After a successful call for proposals, it transitioned into the Joint Video Experts Team (also abbreviated to JVET) in April 2018 with the task to develop a new video coding standard.
The new video coding standard was named Versatile Video Coding (VVC).
四、视频压缩编码的基本技术
视频信号的冗余信息
以记录数字视频的YUV分量格式为例,YUV分别代表亮度与两个色差信号。例如对于现有的PAL制电视系统,其亮度信号采样频率为13.5MHz;色度信号的频带通常为亮度信号的一半或更少,为6.75MHz或3.375MHz。以4:2:2的采样频率为例,Y信号采用13.5MHz,色度信号U和V采用6.75MHz采样,采样信号以8bit量化,则可以计算出数字视频的码率为:
13.5*8 + 6.75*8 + 6.75*8= 216Mbit/s
如此大的数据量如果直接进行存储或传输将会遇到很大困难,因此必须采用压缩技术以减少码率。数字化后的视频信号能进行压缩主要依据两个基本条件:
-
数据冗余。例如如空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着很强的相关性。消除这些冗余并不会导致信息损失,属于无损压缩。
-
视觉冗余。人眼的一些特性比如亮度辨别阈值,视觉阈值,对亮度和色度的敏感度不同,使得在编码的时候引入适量的误差,也不会被察觉出来。可以利用人眼的视觉特性,以一定的客观失真换取数据压缩。这种压缩属于有损压缩。
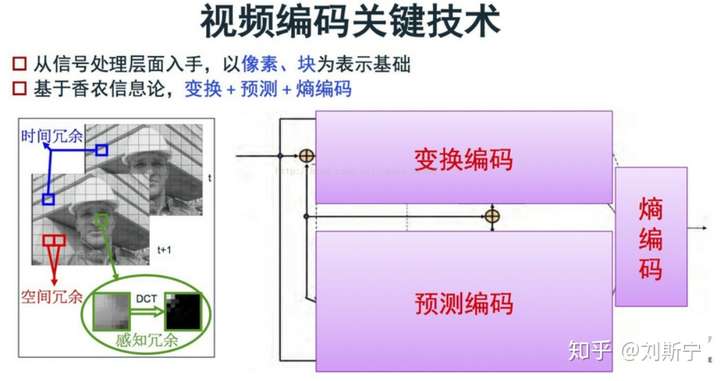
数字视频信号的压缩正是基于上述两种条件,使得视频数据量得以极大的压缩,有利于传输和存储。一般的数字视频压缩编码方法都是混合编码,即将变换编码,运动估计和运动补偿,以及熵编码三种方式相结合来进行压缩编码。通常使用变换编码来消去除图像的帧内冗余,用运动估计和运动补偿来去除图像的帧间冗余,用熵编码来进一步提高压缩的效率。下文简单介绍这三种压缩编码方法。
为了专门处理视频信息中的多种冗余,视频压缩编码采用了多种技术来提高视频的压缩比率。其中常见的有预测编码、变换编码和熵编码等。
1. 变换编码 目前主流的视频编码算法均属于有损编码,通过对视频造成有限而可以容忍的损失,获取相对更高的编码效率。而造成信息损失的部分即在于变换量化这一部分。在进行量化之前,首先需要将图像信息从空间域通过变换编码变换至频域,并计算其变换系数供后续的编码。 在视频编码算法中通常使用正交变换进行变换编码,常用的正交变换方法有:离散余弦变换(DCT)、离散正弦变换(DST)、K-L变换等。
变换编码的作用是将空间域描述的图像信号变换到频率域,然后对变换后的系数进行编码处理。一般来说,图像在空间上具有较强的相关性,变换到频率域可以实现去相关和能量集中。常用的正交变换有离散傅里叶变换,离散余弦变换等等。数字视频压缩过程中应用广泛的是离散余弦变换。
离散余弦变换简称为DCT变换。它可以将L*L的图像块从空间域变换为频率域。所以,在基于DCT的图像压缩编码过程中,首先需要将图像分成互不重叠的图像块。假设一帧图像的大小为1280*720,首先将其以网格状的形式分成160*90个尺寸为8*8的彼此没有重叠的图像块,接下来才能对每个图像块进行DCT变换。
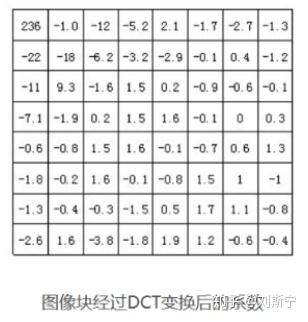
经过分块以后,每个8*8点的图像块被送入DCT编码器,将8*8的图像块从空间域变换为频率域。下图给出一个实际8*8的图像块例子,图中的数字代表了每个像素的亮度值。从图上可以看出,在这个图像块中各个像素亮度值比较均匀,特别是相邻像素亮度值变化不是很大,说明图像信号具有很强的相关性。

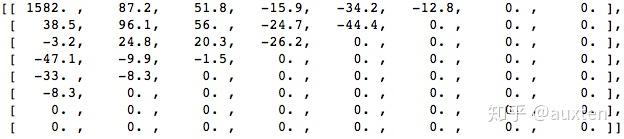
下图是上图中图像块经过DCT变换后的结果。从图中可以看出经过DCT变换后,左上角的低频系数集中了大量能量,而右下角的高频系数上的能量很小。
信号经过DCT变换后需要进行量化。由于人的眼睛对图像的低频特性比如物体的总体亮度之类的信息很敏感,而对图像中的高频细节信息不敏感,因此在传送过程中可以少传或不传送高频信息,只传送低频部分。量化过程通过对低频区的系数进行细量化,高频区的系数进行粗量化,去除了人眼不敏感的高频信息,从而降低信息传送量。因此,量化是一个有损压缩的过程,而且是视频压缩编码中质量损伤的主要原因。
量化的过程可以用下面的公式表示:
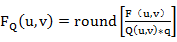
其中FQ(u,v)表示经过量化后的DCT系数;F(u,v)表示量化前的DCT系数;Q(u,v)表示量化加权矩阵;q表示量化步长;round表示归整,即将输出的值取为与之最接近的整数值。
合理选择量化系数,对变换后的图像块进行量化后的结果如图所示。
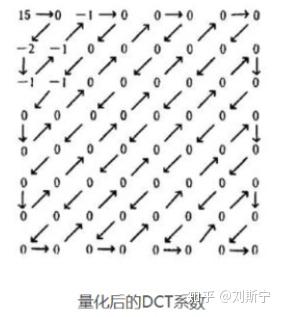
DCT系数经过量化之后大部分经变为0,而只有很少一部分系数为非零值,此时只需将这些非0值进行压缩编码即可。
2. 熵编码 视频编码中的熵编码方法主要用于消除视频信息中的统计冗余。由于信源中每一个符号出现的概率并不一致,这就导致使用同样长度的码字表示所有的符号会造成浪费。通过熵编码,针对不同的语法元素分配不同长度的码元,可以有效消除视频信息中由于符号概率导致的冗余。 在视频编码算法中常用的熵编码方法有变长编码和算术编码等,具体来说主要有上下文自适应的变长编码(CAVLC)和上下文自适应的二进制算术编码(CABAC)。
3. 预测编码
In video compression "prediction" of a block means finding the most“similar” block to the current one among the surrounding blocks.
在视频压缩技术中,“预测”一词指的是在当前像素块周围的一些像素块中找出(或者用一定的方法构造一个)与当前块最“接近”的像素块。
预测编码可以用于处理视频中的时间和空间域的冗余。视频处理中的预测编码主要分为两大类:帧内预测和帧间预测。
帧内预测:预测值与实际值位于同一帧内,用于消除图像的空间冗余;帧内预测的特点是压缩率相对较低,然而可以独立解码,不依赖其他帧的数据;通常视频中的关键帧都采用帧内预测。
帧间预测:帧间预测的实际值位于当前帧,预测值位于参考帧,用于消除图像的时间冗余;帧间预测的压缩率高于帧内预测,然而不能独立解码,必须在获取参考帧数据之后才能重建当前帧。
通常在视频码流中,I帧全部使用帧内编码,P帧/B帧中的数据可能使用帧内或者帧间编码。
运动估计(Motion Estimation)和运动补偿(Motion Compensation)是消除图像序列时间方向相关性的有效手段。上文介绍的DCT变换、量化、熵编码的方法是在一帧图像的基础上进行,通过这些方法可以消除图像内部各像素间在空间上的相关性。实际上图像信号除了空间上的相关性之外,还有时间上的相关性。例如对于像新闻联播这种背景静止,画面主体运动较小的数字视频,每一幅画面之间的区别很小,画面之间的相关性很大。对于这种情况我们没有必要对每一帧图像单独进行编码,而是可以只对相邻视频帧中变化的部分进行编码,从而进一步减小数据量,这方面的工作是由运动估计和运动补偿来实现的。
运动估计技术一般将当前的输入图像分割成若干彼此不相重叠的小图像子块,例如一帧图像的大小为1280*720,首先将其以网格状的形式分成40*45个尺寸为16*16的彼此没有重叠的图像块,然后在前一图像或者后一个图像某个搜索窗口的范围内为每一个图像块寻找一个与之最为相似的图像块。这个搜寻的过程叫做运动估计。通过计算最相似的图像块与该图像块之间的位置信息,可以得到一个运动矢量。这样在编码过程中就可以将当前图像中的块与参考图像运动矢量所指向的最相似的图像块相减,得到一个残差图像块,由于残差图像块中的每个像素值很小,所以在压缩编码中可以获得更高的压缩比。这个相减过程叫运动补偿。
由于编码过程中需要使用参考图像来进行运动估计和运动补偿,因此参考图像的选择显得很重要。一般情况下编码器的将输入的每一帧图像根据其参考图像的不同分成3种不同的类型:I(Intra)帧、B(Bidirection prediction)帧、P(Prediction)帧。如图所示。
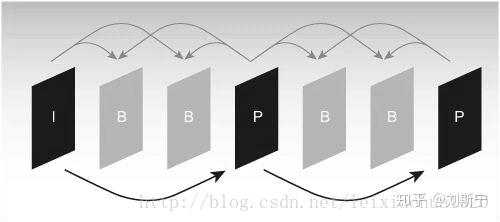
如图所示,I帧只使用本帧内的数据进行编码,在编码过程中它不需要进行运动估计和运动补偿。显然,由于I帧没有消除时间方向的相关性,所以压缩比相对不高。P帧在编码过程中使用一个前面的I帧或P帧作为参考图像进行运动补偿,实际上是对当前图像与参考图像的差值进行编码。B帧的编码方式与P帧相似,惟一不同的地方是在编码过程中它要使用一个前面的I帧或P帧和一个后面的I帧或P帧进行预测。由此可见,每一个P帧的编码需要利用一帧图像作为参考图像,而B帧则需要两帧图像作为参考。相比之下,B帧比P帧拥有更高的压缩比。
4. 混合编码
上面介绍了视频压缩编码过程中的几个重要的方法。在实际应用中这几个方法不是分离的,通常将它们结合起来使用以达到最好的压缩效果。下图给出了混合编码(即变换编码+ 运动估计和运动补偿+ 熵编码)的模型。该模型普遍应用于MPEG1,MPEG2,H.264等标准中。
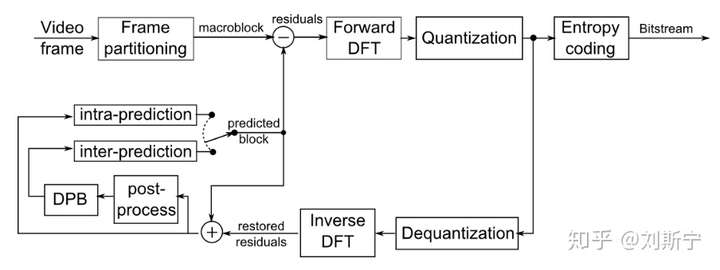
从图中我们可以看到,当前输入的图像首先要经过分块,分块得到的图像块要与经过运动补偿的预测图像相减得到差值图像X,然后对该差值图像块进行DCT变换和量化,量化输出的数据有两个不同的去处:一个是送给熵编码器进行编码,编码后的码流输出到一个缓存器中保存,等待传送出去。另一个应用是进行反量化和反变化后的到信号X’,该信号将与运动补偿输出的图像块相加得到新的预测图像信号,并将新的预测图像块送至帧存储器。
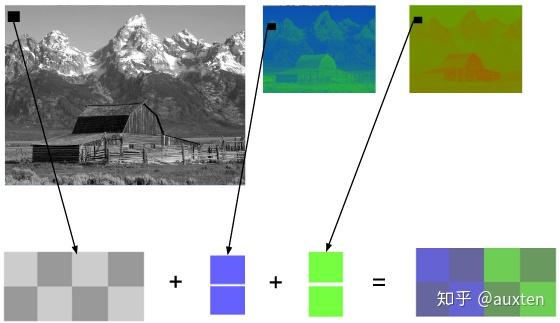
一个图像可以视作一个二维矩阵。如果将色彩考虑进来,我们可以做出推广:将这个图像视作一个三维矩阵——多出来的维度用于储存色彩信息。
如果我们选择三原色(红、绿、蓝)代表这些色彩,这就定义了三个平面:第一个是红色平面,第二个是绿色平面,最后一个是蓝色平面。
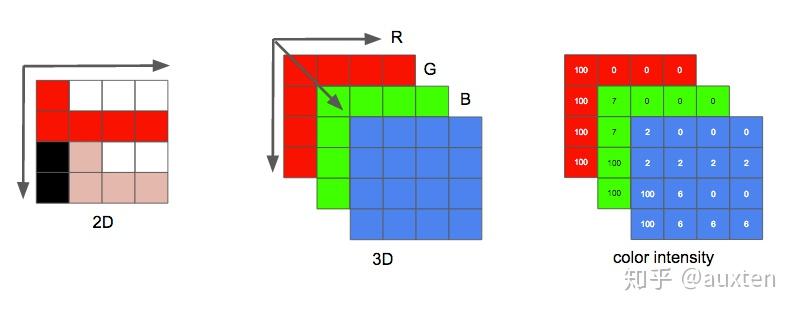
我们把这个矩阵里的每一个点称为像素(图像元素)。像素的色彩由三原色的强度(通常用数值表示)表示。例如,一个红色像素是指强度为 0 的绿色,强度为 0 的蓝色和强度最大的红色。粉色像素可以通过三种颜色的组合表示。如果规定强度的取值范围是 0 到 255,红色 255、绿色 192、蓝色 203 则表示粉色。
编码彩色图像的其它方法
还有许多其它模型也可以用来表示色彩,进而组成图像。例如,给每种颜色都标上序号(如下图),这样每个像素仅需一个字节就可以表示出来,而不是 RGB 模型通常所需的 3 个。在这样一个模型里我们可以用一个二维矩阵来代替三维矩阵去表示我们的色彩,这将节省存储空间,但色彩的数量将会受限。

例如以下几张图片。第一张包含所有颜色平面。剩下的分别是红、绿、蓝色平面(显示为灰调)(译注:颜色强度高的地方显示为亮色,强度低为暗色)。

我们可以看到,对于最终的成像,红色平面对强度的贡献更多(三个平面最亮的是红色平面),蓝色平面(最后一张图片)的贡献大多只在马里奥的眼睛和他衣服的一部分。所有颜色平面对马里奥的胡子(最暗的部分)均贡献较少。
存储颜色的强度,需要占用一定大小的数据空间,这个大小被称为颜色深度。假如每个颜色(平面)的强度占用 8 bit(取值范围为 0 到 255),那么颜色深度就是 24(8*3)bit,我们还可以推导出我们可以使用 2 的 24 次方种不同的颜色。
很棒的学习材料:现实世界的照片是如何拍摄成 0 和 1 的。
图片的另一个属性是分辨率,即一个平面内像素的数量。通常表示成宽*高,例如下面这张 4×4 的图片。
自己动手:玩转图像和颜色
你可以使用 jupyter(python, numpy, matplotlib 等等)玩转图像。
你也可以学习图像滤镜(边缘检测,磨皮,模糊。。。)的原理。
图像或视频还有一个属性是宽高比,它简单地描述了图像或像素的宽度和高度之间的比例关系。
当人们说这个电影或照片是 16:9 时,通常是指显示宽高比(DAR),然而我们也可以有不同形状的单个像素,我们称为像素宽高比(PAR)。

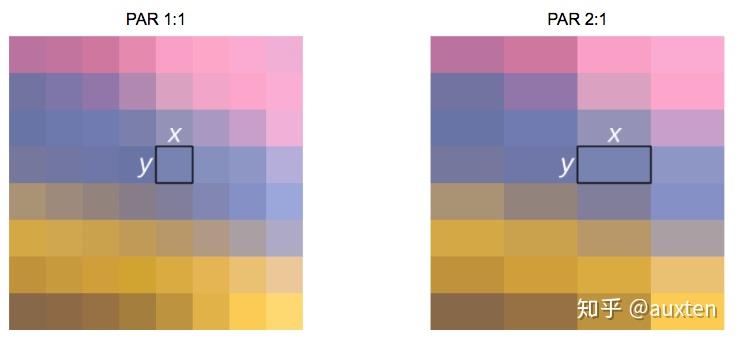
DVD 的 DAR 是 4:3
虽然 DVD 的实际分辨率是 704×480,但它依然保持 4:3 的宽高比,因为它有一个 10:11(704×10/480×11)的 PAR。
现在我们可以将视频定义为在单位时间内连续的 n 帧,这可以视作一个新的维度,n 即为帧率,若单位时间为秒,则等同于 FPS (每秒帧数 Frames Per Second)。
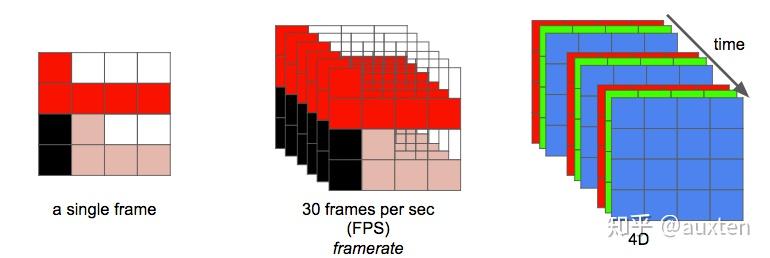
播放一段视频每秒所需的数据量就是它的比特率(即常说的码率)。
比特率 = 宽 * 高 * 颜色深度 * 帧每秒
例如,一段每秒 30 帧,每像素 24 bits,分辨率是 480×240 的视频,如果我们不做任何压缩,它将需要 82,944,000 比特每秒或 82.944 Mbps (30x480x240x24)。
当比特率几乎恒定时称为恒定比特率(CBR);但它也可以变化,称为可变比特率(VBR)。
这个图形显示了一个受限的 VBR,当帧为黑色时不会花费太多的数据量。

在早期,工程师们想出了一项技术能将视频的感官帧率加倍而没有消耗额外带宽。这项技术被称为隔行扫描;总的来说,它在一个时间点发送一个画面——画面用于填充屏幕的一半,而下一个时间点发送的画面用于填充屏幕的另一半。
如今的屏幕渲染大多使用逐行扫描技术。这是一种显示、存储、传输运动图像的方法,每帧中的所有行都会被依次绘制。

现在我们知道了数字化图像的原理;它的颜色的编排方式;给定帧率和分辨率时,展示一个视频需要花费多少比特率;它是恒定的(CBR)还是可变的(VBR);还有很多其它内容,如隔行扫描和 PAR。
自己动手:检查视频属性
你可以使用 ffmpeg 或 mediainfo 检查大多数属性的解释。
消除冗余
我们认识到,不对视频进行压缩是不行的;一个单独的一小时长的视频,分辨率为 720p 和 30fps 时将需要 278GB*。仅仅使用无损数据压缩算法——如 DEFLATE(被PKZIP, Gzip, 和 PNG 使用)——也无法充分减少视频所需的带宽,我们需要找到其它压缩视频的方法。
*我们使用乘积得出这个数字 1280 x 720 x 24 x 30 x 3600 (宽,高,每像素比特数,fps 和秒数)
为此,我们可以利用视觉特性:和区分颜色相比,我们区分亮度要更加敏锐。时间上的重复:一段视频包含很多只有一点小小改变的图像。图像内的重复:每一帧也包含很多颜色相同或相似的区域。
颜色,亮度和我们的眼睛
我们的眼睛对亮度比对颜色更敏感,你可以看看下面的图片自己测试。

如果你看不出左图的方块 A 和方块 B 的颜色是相同的,那么好,是我们的大脑玩了一个小把戏,这让我们更多的去注意光与暗,而不是颜色。右边这里有一个使用同样颜色的连接器,那么我们(的大脑)就能轻易分辨出事实,它们是同样的颜色。
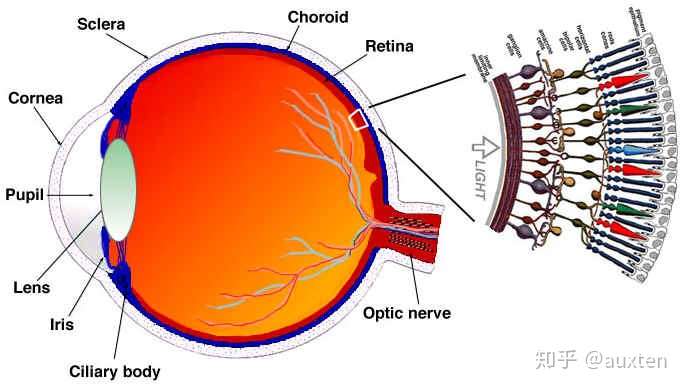
简单解释我们的眼睛工作的原理
眼睛是一个复杂的器官,有许多部分组成,但我们最感兴趣的是视锥细胞和视杆细胞。眼睛有大约1.2亿个视杆细胞和6百万个视锥细胞。
简单来说,让我们把颜色和亮度放在眼睛的功能部位上。视杆细胞主要负责亮度,而视锥细胞负责颜色,有三种类型的视锥,每个都有不同的颜料,叫做:S-视锥(蓝色),M-视锥(绿色)和L-视锥(红色)。
既然我们的视杆细胞(亮度)比视锥细胞多很多,一个合理的推断是相比颜色,我们有更好的能力去区分黑暗和光亮。
一旦我们知道我们对亮度(图像中的亮度)更敏感,我们就可以利用它。
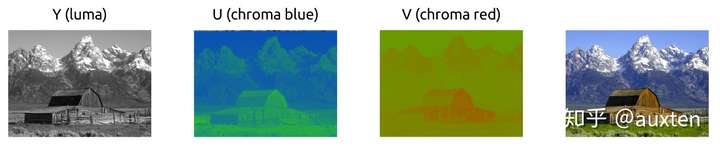
颜色模型
我们最开始学习的彩色图像的原理使用的是 RGB 模型,但也有其他模型。有一种模型将亮度(光亮)和色度(颜色)分离开,它被称为 YCbCr*。
* 有很多种模型做同样的分离。
这个颜色模型使用 Y 来表示亮度,还有两种颜色通道:Cb(蓝色色度) 和 Cr(红色色度)。YCbCr 可以由 RGB 转换得来,也可以转换回 RGB。使用这个模型我们可以创建拥有完整色彩的图像,如下图。
YCbCr 和 RGB 之间的转换
有人可能会问,在不使用绿色(色度)的情况下,我们如何表现出所有的色彩?
为了回答这个问题,我们将介绍从 RGB 到 YCbCr 的转换。我们将使用 ITU-R 小组*建议的标准 BT.601 中的系数。
第一步是计算亮度,我们将使用 ITU 建议的常量,并替换 RGB 值。
Y = 0.299R + 0.587G + 0.114B
一旦我们有了亮度后,我们就可以拆分颜色(蓝色色度和红色色度):
Cb = 0.564(B - Y) Cr = 0.713(R - Y) # 并且我们也可以使用 YCbCr 转换回来,甚至得到绿色。 R = Y + 1.402Cr B = Y + 1.772Cb G = Y - 0.344Cb - 0.714Cr
*组织和标准在数字视频领域中很常见,它们通常定义什么是标准,例如,什么是 4K?我们应该使用什么帧率?分辨率?颜色模型?
通常,显示屏(监视器,电视机,屏幕等等)仅使用 RGB 模型,并以不同的方式来组织,看看下面这些放大效果:

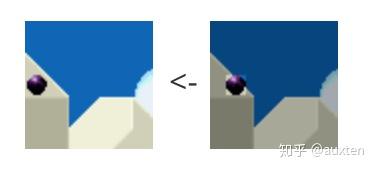
色度子采样
一旦我们能从图像中分离出亮度和色度,我们就可以利用人类视觉系统对亮度比色度更敏感的特点,选择性地剔除信息。色度子采样是一种编码图像时,使色度分辨率低于亮度的技术。

我们应该减少多少色度分辨率呢?已经有一些模式定义了如何处理分辨率和合并(最终的颜色 = Y + Cb + Cr)。
这些模式称为子采样系统,并被表示为 3 部分的比率 – a:x:y,其定义了色度平面的分辨率,与亮度平面上的、分辨率为 a x 2 的小块之间的关系。
-
a是水平采样参考 (通常是 4), -
x是第一行的色度样本数(相对于 a 的水平分辨率), -
y是第二行的色度样本数。
存在的一个例外是 4:1:0,其在每个亮度平面分辨率为 4 x 4 的块内提供一个色度样本。
现代编解码器中使用的常用方案是: 4:4:4 (没有子采样)**, 4:2:2, 4:1:1, 4:2:0, 4:1:0 and 3:1:1。
YCbCr 4:2:0 合并
这是使用 YCbCr 4:2:0 合并的一个图像的一块,注意我们每像素只花费 12bit。
下图是同一张图片使用几种主要的色度子采样技术进行编码,第一行图像是最终的 YCbCr,而最后一行图像展示了色度的分辨率。这么小的损失确实是一个伟大的胜利。

前面我们计算过我们需要 278GB 去存储一个一小时长,分辨率在720p和30fps的视频文件。如果我们使用 YCbCr 4:2:0 我们能剪掉一半的大小(139GB)*,但仍然不够理想。
* 我们通过将宽、高、颜色深度和 fps 相乘得出这个值。前面我们需要 24 bit,现在我们只需要 12 bit。
自己动手:检查 YCbCr 直方图
你可以使用 ffmpeg 检查 YCbCr 直方图。这个场景有更多的蓝色贡献,由直方图显示。

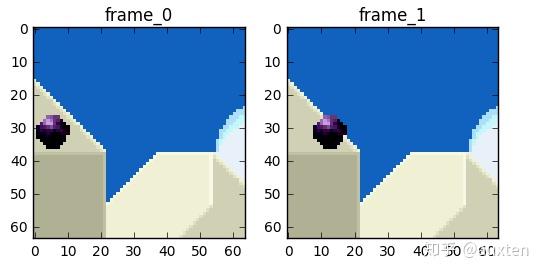
帧类型
现在我们进一步消除时间冗余,但在这之前让我们来确定一些基本术语。假设我们一段 30fps 的影片,这是最开始的 4 帧。

我们可以在帧内看到很多重复内容,如蓝色背景,从 0 帧到第 3 帧它都没有变化。为了解决这个问题,我们可以将它们抽象地分类为三种类型的帧。
I 帧(帧内编码,关键帧)
I 帧(可参考,关键帧,帧内编码)是一个自足的帧。它不依靠任何东西来渲染,I 帧与静态图片相似。第一帧通常是 I 帧,但我们将看到 I 帧被定期插入其它类型的帧之间。

P 帧(预测)
P 帧利用了一个事实:当前的画面几乎总能使用之前的一帧进行渲染。例如,在第二帧,唯一的改变是球向前移动了。仅仅使用(第二帧)对前一帧的引用和差值,我们就能重建前一帧。
自己动手:具有单个 I 帧的视频
既然 P 帧使用较少的数据,为什么我们不能用单个 I 帧和其余的 P 帧来编码整个视频?
编码完这个视频之后,开始观看它,并快进到视频的末尾部分,你会注意到它需要花一些时间才真正跳转到这部分。这是因为 P 帧需要一个引用帧(比如 I 帧)才能渲染。
你可以做的另一个快速试验,是使用单个 I 帧编码视频,然后再次编码且每 2 秒插入一个 I 帧,并比较成品的大小。
B 帧(双向预测)
如何引用前面和后面的帧去做更好的压缩?!简单地说 B 帧就是这么做的。

自己动手:使用 B 帧比较视频
你可以生成两个版本,一个使用 B 帧,另一个全部不使用 B 帧,然后查看文件的大小以及画质。
小结
这些帧类型用于提供更好的压缩率,我们将在下一章看到这是如何发生的。现在,我们可以想到 I 帧是昂贵的,P 帧是便宜的,最便宜的是 B 帧。

时间冗余(帧间预测)
让我们探究去除时间上的重复,去除这一类冗余的技术就是帧间预测。
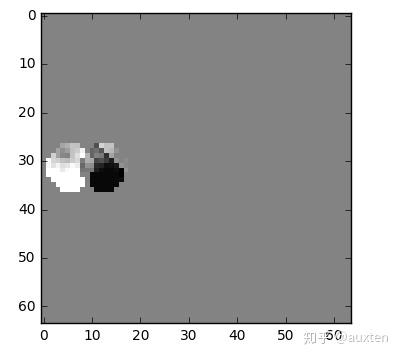
我们将尝试花费较少的数据量去编码在时间上连续的 0 号帧和 1 号帧。
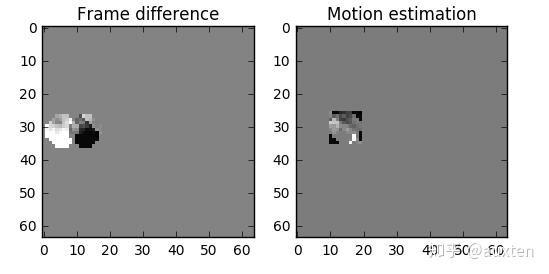
我们可以做个减法,我们简单地用 0 号帧减去 1 号帧,得到残差,这样我们就只需要对残差进行编码。
但我们有一个更好的方法来节省数据量。首先,我们将0 号帧 视为一个个分块的集合,然后我们将尝试将 帧 1 和 帧 0 上的块相匹配。我们可以将这看作是运动预测。
维基百科—块运动补偿
“运动补偿是一种描述相邻帧(相邻在这里表示在编码关系上相邻,在播放顺序上两帧未必相邻)差别的方法,具体来说是描述前面一帧(相邻在这里表示在编码关系上的前面,在播放顺序上未必在当前帧前面)的每个小块怎样移动到当前帧中的某个位置去。”
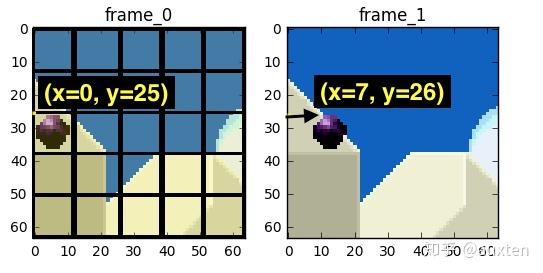
我们预计那个球会从 x=0, y=25 移动到 x=6, y=26,x 和 y 的值就是运动向量。进一步节省数据量的方法是,只编码这两者运动向量的差。所以,最终运动向量就是 x=6 (6-0), y=1 (26-25)。
实际情况下,这个球会被切成 n 个分区,但处理过程是相同的。
帧上的物体以三维方式移动,当球移动到背景时会变小。当我们尝试寻找匹配的块,找不到完美匹配的块是正常的。这是一张运动预测与实际值相叠加的图片。
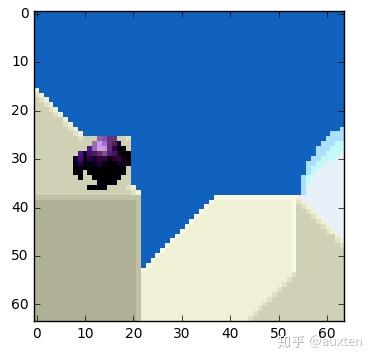
但我们能看到当我们使用运动预测时,编码的数据量少于使用简单的残差帧技术。
你可以使用 jupyter 玩转这些概念。
自己动手:查看运动向量
我们可以使用 ffmpeg 生成包含帧间预测(运动向量)的视频。

或者我们也可使用 Intel® Video Pro Analyzer(需要付费,但也有只能查看前 10 帧的免费试用版)。
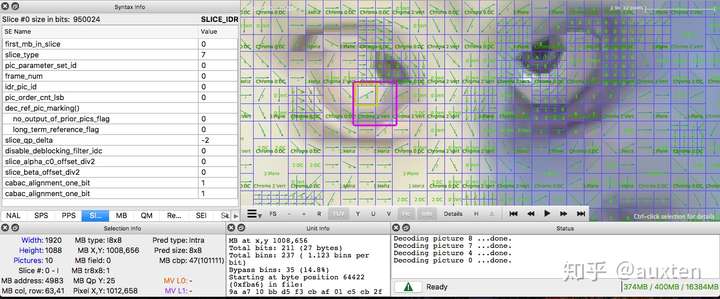
视频编解码器是如何工作的?
是什么? 就是用于压缩或解压数字视频的软件或硬件。为什么? 人们需要在有限带宽或存储空间下提高视频的质量。还记得当我们计算每秒 30 帧,每像素 24 bit,分辨率是 480×240 的视频需要多少带宽吗?没有压缩时是 82.944 Mbps。电视或互联网提供 HD/FullHD/4K 只能靠视频编解码器。怎么做? 我们将简单介绍一下主要的技术。
视频编解码 vs 容器
初学者一个常见的错误是混淆数字视频编解码器和数字视频容器。我们可以将容器视为包含视频(也很可能包含音频)元数据的包装格式,压缩过的视频可以看成是它承载的内容。
通常,视频文件的格式定义其视频容器。例如,文件video.mp4可能是 MPEG-4 Part 14 容器,一个叫video.mkv的文件可能是 matroska。我们可以使用 ffmpeg 或 mediainfo 来完全确定编解码器和容器格式。
历史
在我们跳进通用编解码器内部工作之前,让我们回头了解一些旧的视频编解码器。
视频编解码器 H.261 诞生在 1990(技术上是 1988),被设计为以 64 kbit/s 的数据速率工作。它已经使用如色度子采样、宏块,等等理念。在 1995 年,H.263 视频编解码器标准被发布,并继续延续到 2001 年。
在 2003 年 H.264/AVC 的第一版被完成。在同一年,一家叫做 TrueMotion 的公司发布了他们的免版税有损视频压缩的视频编解码器,称为 VP3。在 2008 年,Google 收购了这家公司,在同一年发布 VP8。在 2012 年 12 月,Google 发布了 VP9,市面上大约有 3/4 的浏览器(包括手机)支持。
AV1 是由 Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel, Cisco 等公司组成的开放媒体联盟(AOMedia)设计的一种新的视频编解码器,免版税,开源。第一版 0.1.0 参考编解码器发布于 2016 年 4 月 7 号。

AV1 的诞生
2015 年早期,Google 正在 VP10 上工作,Xiph (Mozilla) 正在 Daala 上工作,Cisco 开源了它的称为 Thor 的免版税视频编解码器。
接着 MPEG LA 宣布了 HEVC (H.265) 每年版税的的上限,比 H.264 高 8 倍,但很快他们又再次改变了条款:
-
不设年度收费上限
-
收取内容费(收入的 0.5%)
-
每单位费用高于 h264 的 10 倍
开放媒体联盟由硬件厂商(Intel, AMD, ARM , Nvidia, Cisco),内容分发商(Google, Netflix, Amazon),浏览器维护者(Google, Mozilla),等公司创建。
这些公司有一个共同目标,一个免版税的视频编解码器,所以 AV1 诞生时使用了一个更简单的专利许可证。Timothy B. Terriberry 做了一个精彩的介绍,关于 AV1 的概念,许可证模式和它当前的状态,就是本节的来源。
前往 http://aomanalyzer.org/, 你会惊讶于使用你的浏览器就可以分析 AV1 编解码器。
附:如果你想了解更多编解码器的历史,你需要了解视频压缩专利背后的基本知识。
通用编解码器
我们接下来要介绍通用视频编解码器背后的主要机制,大多数概念都很实用,并被现代编解码器如 VP9, AV1 和 HEVC 使用。需要注意:我们将简化许多内容。有时我们会使用真实的例子(主要是 H.264)来演示技术。
第一步 – 图片分区
第一步是将帧分成几个分区,子分区甚至更多。

但是为什么呢?有许多原因,比如,当我们分割图片时,我们可以更精确的处理预测,在微小移动的部分使用较小的分区,而在静态背景上使用较大的分区。
通常,编解码器将这些分区组织成切片(或瓦片),宏(或编码树单元)和许多子分区。这些分区的最大大小有所不同,HEVC 设置成 64×64,而 AVC 使用 16×16,但子分区可以达到 4×4 的大小。
还记得我们学过的帧的分类吗?你也可以把这些概念应用到块,因此我们可以有 I 切片,B 切片,I 宏块等等。
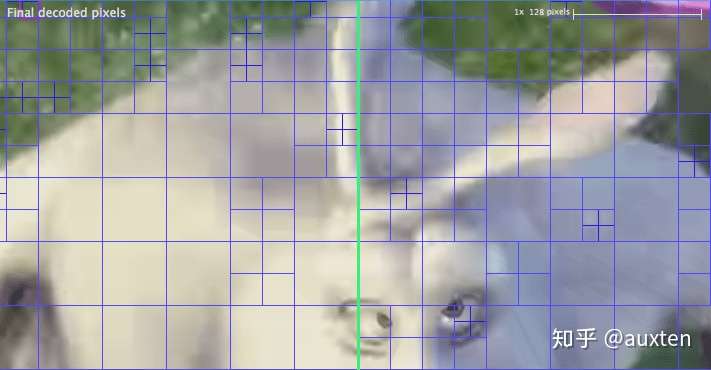
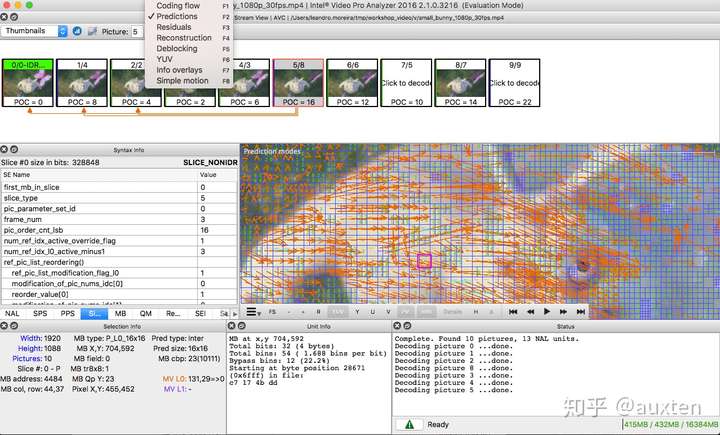
自己动手:查看分区
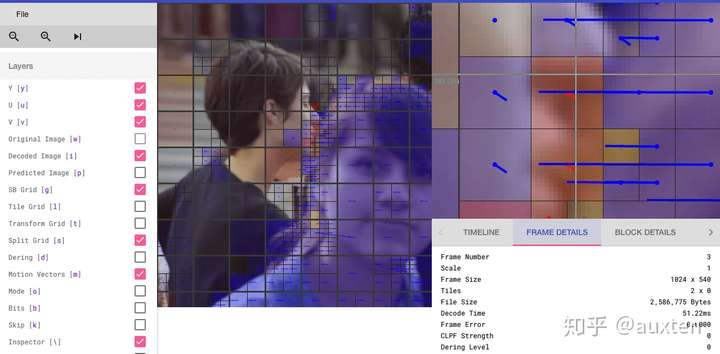
我们也可以使用 Intel® Video Pro Analyzer(需要付费,但也有只能查看前 10 帧的免费试用版)。这是 VP9 分区的分析。
第二步 – 预测
一旦我们有了分区,我们就可以在它们之上做出预测。对于帧间预测,我们需要发送运动向量和残差;至于帧内预测,我们需要发送预测方向和残差。
第三步 – 转换
在我们得到残差块(预测分区-真实分区)之后,我们可以用一种方式变换它,这样我们就知道哪些像素我们应该丢弃,还依然能保持整体质量。这个确切的行为有几种变换方式。
尽管有其它的变换方式,但我们重点关注离散余弦变换(DCT)。DCT 的主要功能有:
-
将像素块转换为相同大小的频率系数块。
-
压缩能量,更容易消除空间冗余。
-
可逆的,也意味着你可以还原回像素。
2017 年 2 月 2 号,F. M. Bayer 和 R. J. Cintra 发表了他们的论文:图像压缩的 DCT 类变换只需要 14 个加法。
如果你不理解每个要点的好处,不用担心,我们会尝试进行一些实验,以便从中看到真正的价值。
我们来看下面的像素块(8×8):
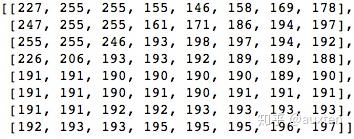
下面是其渲染的块图像(8×8):

当我们对这个像素块应用 DCT 时, 得到如下系数块(8×8):

接着如果我们渲染这个系数块,就会得到这张图片:
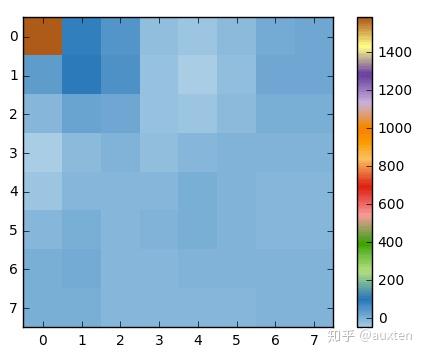
如你所见它看起来完全不像原图像,我们可能会注意到第一个系数与其它系数非常不同。第一个系数被称为直流分量,代表了输入数组中的所有样本,有点类似于平均值。
这个系数块有一个有趣的属性:高频部分和低频部分是分离的。
在一张图像中,大多数能量会集中在低频部分,所以如果我们将图像转换成频率系数,并丢掉高频系数,我们就能减少描述图像所需的数据量,而不会牺牲太多的图像质量。
频率是指信号变化的速度。
让我们通过实验学习这点,我们将使用 DCT 把原始图像转换为频率(系数块),然后丢掉最不重要的系数。
首先,我们将它转换为其频域。
然后我们丢弃部分(67%)系数,主要是它的右下角部分。
然后我们从丢弃的系数块重构图像(记住,这需要可逆),并与原始图像相比较。
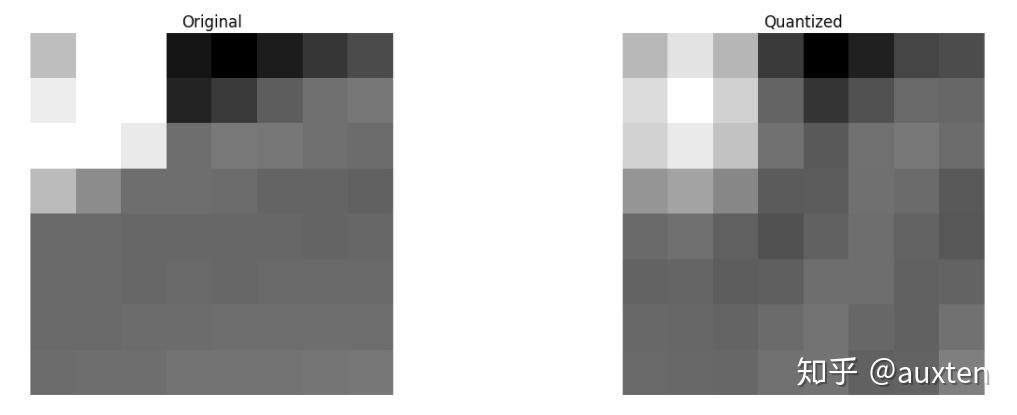
如我们所见它酷似原始图像,但它引入了许多与原来的不同,我们丢弃了67.1875%,但我们仍然得到至少类似于原来的东西。我们可以更加智能的丢弃系数去得到更好的图像质量,但这是下一个主题。
使用全部像素形成每个系数
重要的是要注意,每个系数并不直接映射到单个像素,但它是所有像素的加权和。这个神奇的图形展示了如何计算出第一和第二个系数,使用每个唯一的索引做权重。
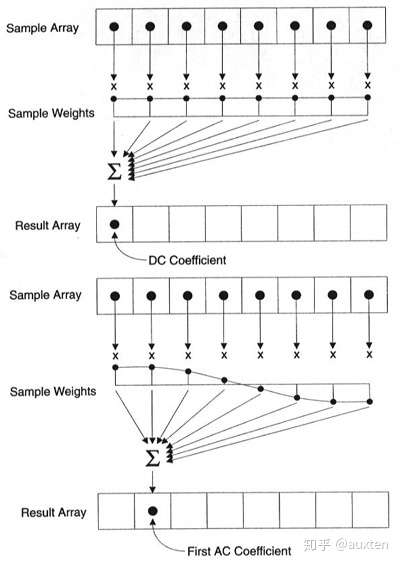
来源:https://web.archive.org/web/20150129171151/https://www.iem.thm.de/telekom-labor/zinke/mk/mpeg2beg/whatisit.htm
你也可以尝试通过查看在 DCT 基础上形成的简单图片来可视化 DCT。例如,这是使用每个系数权重形成的字符 A。
自己动手:丢弃不同的系数
你可以玩转 DCT 变换
第四步 – 量化
当我们丢弃一些系数时,在最后一步(变换),我们做了一些形式的量化。这一步,我们选择性地剔除信息(有损部分)或者简单来说,我们将量化系数以实现压缩。
我们如何量化一个系数块?一个简单的方法是均匀量化,我们取一个块并将其除以单个的值(10),并舍入值。

我们如何逆转(重新量化)这个系数块?我们可以通过乘以我们先前除以的相同的值(10)来做到。

这不是最好的方法,因为它没有考虑到每个系数的重要性,我们可以使用一个量化矩阵来代替单个值,这个矩阵可以利用 DCT 的属性,多量化右下部,而少(量化)左上部,JPEG 使用了类似的方法,你可以通过查看源码看看这个矩阵。
自己动手:量化
你可以玩转量化
第五步 – 熵编码
在我们量化数据(图像块/切片/帧)之后,我们仍然可以以无损的方式来压缩它。有许多方法(算法)可用来压缩数据。我们将简单体验其中几个,你可以阅读这本很棒的书去深入理解:Understanding Compression: Data Compression for Modern Developers。
VLC 编码:
让我们假设我们有一个符号流:a, e, r 和 t,它们的概率(从0到1)由下表所示。

我们可以分配不同的二进制码,(最好是)小的码给最可能(出现的字符),大些的码给最少可能(出现的字符)。

让我们压缩 eat 流,假设我们为每个字符花费 8 bit,在没有做任何压缩时我们将花费 24 bit。但是在这种情况下,我们使用各自的代码来替换每个字符,我们就能节省空间。
第一步是编码字符 e 为 10,第二个字符是 a,追加(不是数学加法)后是 [10][0],最后是第三个字符 t,最终组成已压缩的比特流 [10][0][1110] 或 1001110,这只需 7 bit(比原来的空间少 3.4 倍)。
请注意每个代码必须是唯一的前缀码,Huffman 能帮你找到这些数字。虽然它有一些问题,但是视频编解码器仍然提供该方法,它也是很多应用程序的压缩算法。
编码器和解码器都必须知道这个(包含编码的)字符表,因此,你也需要传送这个表。
算术编码
让我们假设我们有一个符号流:a, e, r, s 和 t,它们的概率由下表所示。
aerst概率0.30.30.150.050.2考虑到这个表,我们可以构建一个区间,区间包含了所有可能的字符,字符按出现概率排序。

让我们编码 eat 流,我们选择第一个字符 e 位于 0.3 到 0.6 (但不包括 0.6)的子区间,我们选择这个子区间,按照之前同等的比例再次分割。

让我们继续编码我们的流 eat,现在使第二个 a 字符位于 0.3 到 0.39 的区间里,接着再次用同样的方法编码最后的字符 t,得到最后的子区间 0.354 到 0.372。
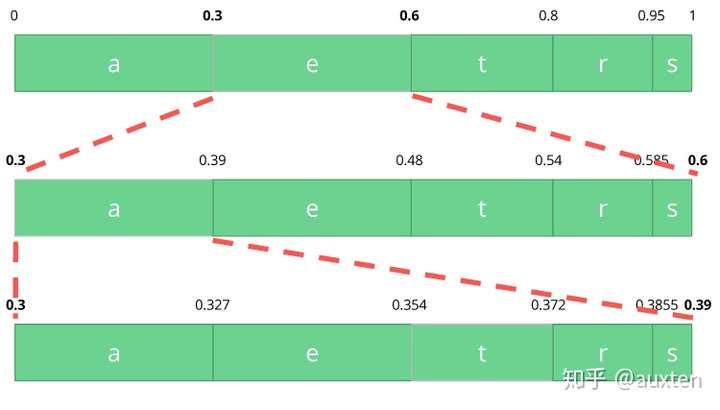
我们只需从最后的子区间 0.354 到 0.372 里选择一个数,让我们选择 0.36,不过我们可以选择这个子区间里的任何数。仅靠这个数,我们将可以恢复原始流 eat。就像我们在区间的区间里画了一根线来编码我们的流。
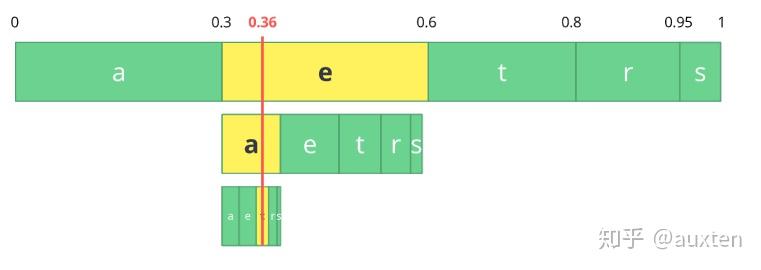
反向过程(又名解码)一样简单,用数字 0.36 和我们原始区间,我们可以进行同样的操作,不过现在是使用这个数字来还原被编码的流。
在第一个区间,我们发现数字落入了一个子区间,因此,这个子区间是我们的第一个字符,现在我们再次切分这个子区间,像之前一样做同样的过程。我们会注意到 0.36 落入了 a 的区间,然后我们重复这一过程直到得到最后一个字符 t(形成我们原始编码过的流 eat)。
编码器和解码器都必须知道字符概率表,因此,你也需要传送这个表。
非常巧妙,不是吗?人们能想出这样的解决方案实在是太聪明了,一些视频编解码器使用这项技术(或至少提供这一选择)。
关于无损压缩量化比特流的办法,这篇文章无疑缺少了很多细节、原因、权衡等等。作为一个开发者你应该学习更多。刚入门视频编码的人可以尝试使用不同的熵编码算法,如ANS。
自己动手:CABAC vs CAVLC
你可以生成两个流,一个使用 CABAC,另一个使用 CAVLC,并比较生成每一个的时间以及最终的大小。
第六步 – 比特流格式
完成所有这些步之后,我们需要将压缩过的帧和内容打包进去。需要明确告知解码器编码定义,如颜色深度,颜色空间,分辨率,预测信息(运动向量,帧内预测方向),配置,层级,帧率,帧类型,帧号等等更多信息。
* 译注:原文为 profile 和 level,没有通用的译名
我们将简单地学习 H.264 比特流。第一步是生成一个小的 H.264* 比特流,可以使用本 repo 和 ffmpeg 来做。
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264
* ffmpeg 默认将所有参数添加为 SEI NAL,很快我们会定义什么是 NAL。
这个命令会使用下面的图片作为帧,生成一个具有单个帧,64×64 和颜色空间为 yuv420 的原始 h264 比特流。

H.264 比特流
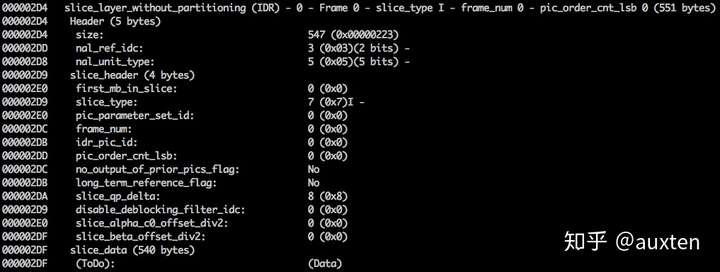
AVC (H.264) 标准规定信息将在宏帧(网络概念上的)内传输,称为 NAL(网络抽象层)。NAL 的主要目标是提供“网络友好”的视频呈现方式,该标准必须适用于电视(基于流),互联网(基于数据包)等。

同步标记用来定义 NAL 单元的边界。每个同步标记的值固定为 0x00 0x00 0x01 ,最开头的标记例外,它的值是 0x00 0x00 0x00 0x01 。如果我们在生成的 h264 比特流上运行 hexdump,我们可以在文件的开头识别至少三个 NAL。
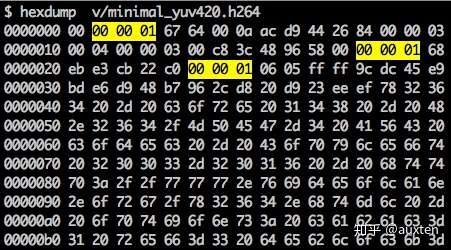
我们之前说过,解码器需要知道不仅仅是图片数据,还有视频的详细信息,如:帧、颜色、使用的参数等。每个 NAL 的第一位定义了其分类和类型。
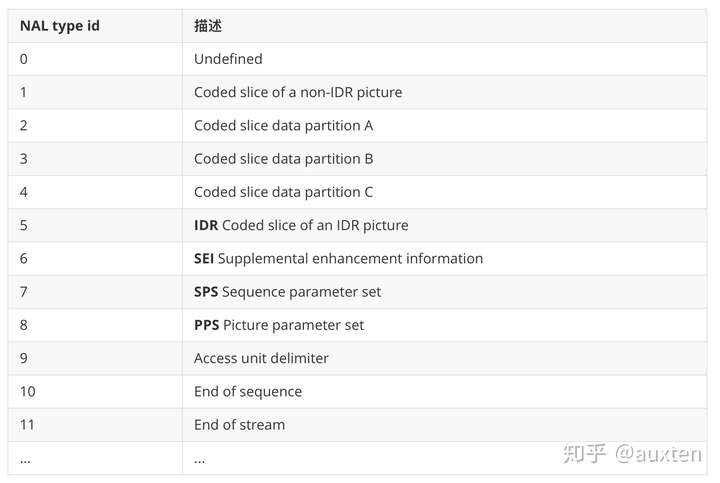
通常,比特流的第一个 NAL 是 SPS,这个类型的 NAL 负责传达通用编码参数,如配置,层级,分辨率等。
如果我们跳过第一个同步标记,就可以通过解码第一个字节来了解第一个 NAL 的类型。
例如同步标记之后的第一个字节是 01100111,第一位(0)是 forbidden_zero_bit 字段,接下来的两位(11)告诉我们是 nal_ref_idc 字段,其表示该 NAL 是否是参考字段,其余 5 位(00111)告诉我们是 nal_unit_type 字段,在这个例子里是 NAL 单元 SPS (7)。
SPS NAL 的第 2 位 (binary=01100100, hex=0x64, dec=100) 是 profile_idc 字段,显示编码器使用的配置,在这个例子里,我们使用受限高配置,一种没有 B(双向预测) 切片支持的高配置。

当我们阅读 SPS NAL 的 H.264 比特流规范时,会为参数名称,分类和描述找到许多值,例如,看看字段 pic_width_in_mbs_minus_1 和 pic_height_in_map_units_minus_1。
参数名称分类描述

ue(v): 无符号整形 Exp-Golomb-coded
如果我们对这些字段的值进行一些计算,将最终得出分辨率。我们可以使用值为 119( (119 + 1) * macroblock_size = 120 * 16 = 1920)的 pic_width_in_mbs_minus_1 表示 1920 x 1080,再次为了减少空间,我们使用 119 来代替编码 1920。
如果我们再次使用二进制视图检查我们创建的视频 (ex: xxd -b -c 11 v/minimal_yuv420.h264),可以跳到帧自身上一个 NAL。

我们可以看到最开始的 6 个字节:01100101 10001000 10000100 00000000 00100001 11111111。我们已经知道第一个字节告诉我们 NAL 的类型,在这个例子里, (00101) 是 IDR 切片 (5),可以进一步检查它:
对照规范,我们能解码切片的类型(slice_type),帧号(frame_num)等重要字段。
为了获得一些字段(ue(v), me(v), se(v) 或 te(v))的值,我们需要称为 Exponential-Golomb 的特定解码器来解码它。当存在很多默认值时,这个方法编码变量值特别高效。
这个视频里 slice_type 和 frame_num 的值是 7(I 切片)和 0(第一帧)。
我们可以将比特流视为一个协议,如果你想学习更多关于比特流的内容,请参考 ITU H.264 规范。这个宏观图展示了图片数据(压缩过的 YUV)所在的位置。
我们可以探究其它比特流,如 VP9 比特流,H.265(HEVC)或是我们的新朋友 AV1 比特流,他们很相似吗?不,但只要学习了其中之一,学习其他的就简单多了。
自己动手:检查 H.264 比特流
我们可以生成一个单帧视频,使用 mediainfo 检查它的 H.264 比特流。事实上,你甚至可以查看解析 h264(AVC) 视频流的源代码。
我们也可使用 Intel® Video Pro Analyzer,需要付费,但也有只能查看前 10 帧的免费试用版,这已经够达成学习目的了。
回顾
我们可以看到我们学了许多使用相同模型的现代编解码器。事实上,让我们看看 Thor 视频编解码器框图,它包含所有我们学过的步骤。你现在应该能更好地理解数字视频领域内的创新和论文。
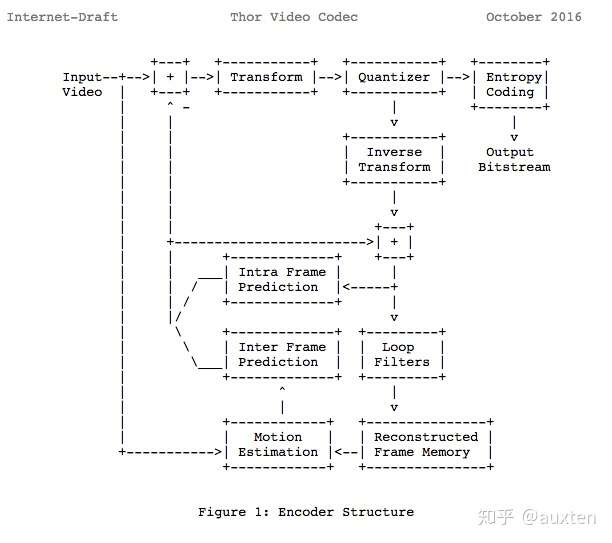
之前我们计算过我们需要 139GB 来保存一个一小时,720p 分辨率和30fps的视频文件,如果我们使用在这里学过的技术,如帧间和帧内预测,转换,量化,熵编码和其它我们能实现——假设我们每像素花费 0.031 bit——同样观感质量的视频,对比 139GB 的存储,只需 367.82MB。
我们根据这里提供的示例视频选择每像素使用 0.031 bit。
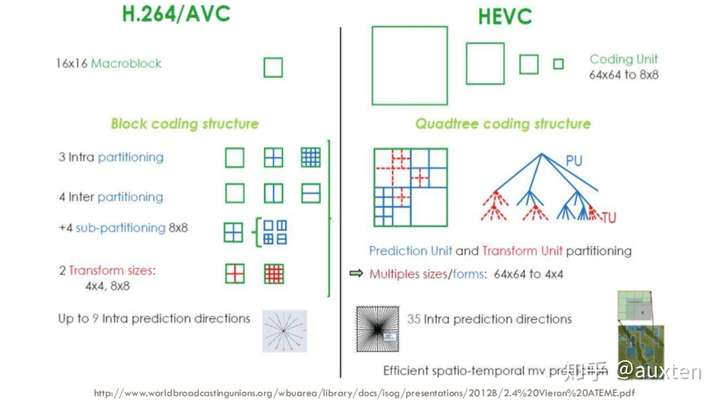
H.265 如何实现比 H.264 更好的压缩率
我们已经更多地了解了编解码器的工作原理,那么就容易理解新的编解码器如何使用更少的数据量传输更高分辨率的视频。
我们将比较 AVC 和 HEVC,要记住的是:我们几乎总是要在压缩率和更多的 CPU 周期(复杂度)之间作权衡。
HEVC 比 AVC 有更大和更多的分区(和子分区)选项,更多帧内预测方向,改进的熵编码等,所有这些改进使得 H.265 比 H.264 的压缩率提升 50%。
在线流媒体通用架构
渐进式下载和自适应流

内容保护
我们可以用一个简单的令牌认证系统来保护视频。用户需要拥有一个有效的令牌才可以播放视频,CDN 会拒绝没有令牌的用户的请求。它与大多数网站的身份认证系统非常相似。
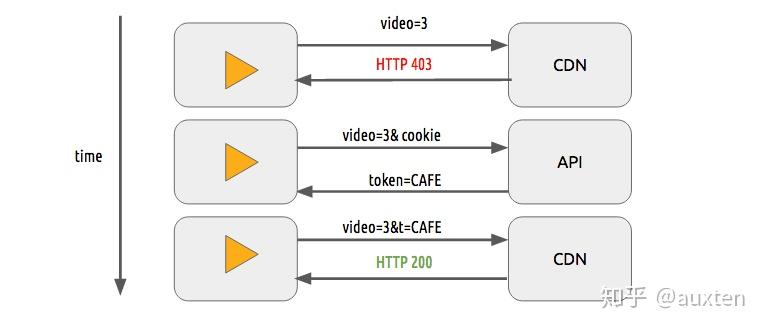
仅仅使用令牌认证系统,用户仍然可以下载并重新分发视频。DRM 系统可以用来避免这种情况。
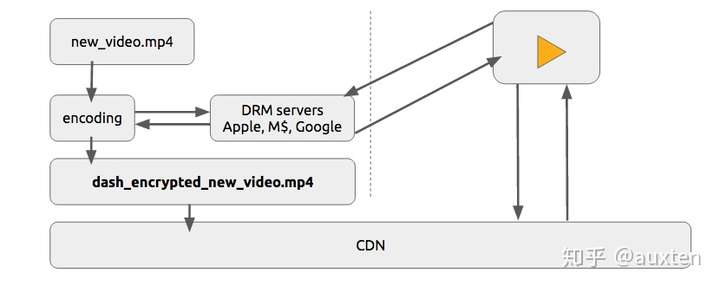
实际情况下,人们通常同时使用这两种技术提供授权和认证。
DRM
主要系统
-
FPS – FairPlay Streaming
-
PR – PlayReady
-
WV – Widevine
DRM 指的是数字版权管理,是一种为数字媒体提供版权保护的方法,例如数字视频和音频。尽管用在了很多场合,但它并没有被普遍接受.
内容的创作者(大多是工作室/制片厂)希望保护他们的知识产权,使他们的数字媒体免遭未经授权的分发。
我们将用一种简单的、抽象的方式描述 DRM
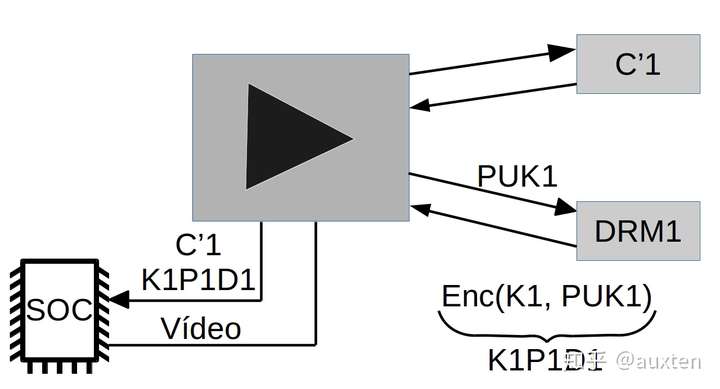
现有一份内容 C1(如 HLS 或 DASH 视频流),一个播放器 P1(如 shaka-clappr, exo-player 或 iOS),装在设备 D1(如智能手机、电视或台式机/笔记本)上,使用 DRM 系统 DRM1(如 FairPlay Streaming, PlayReady, Widevine)
内容 C1 由 DRM1 用一个对称密钥 K1 加密,生成加密内容 C'1

设备 D1 上的播放器 P1 有一个非对称密钥对,密钥对包含一个私钥 PRK1(这个密钥是受保护的1,只有 D1 知道密钥内容),和一个公钥 PUK1
1受保护的: 这种保护可以通过硬件进行保护,例如, 将这个密钥存储在一个特殊的芯片(只读)中,芯片的工作方式就像一个用来解密的[黑箱]。 或通过软件进行保护(较低的安全系数)。DRM 系统提供了识别设备所使用的保护类型的方法。
当 播放器 P1 希望播放****加密内容 C'1 时,它需要与 DRM1 协商,将公钥 PUK1 发送给 DRM1, DRM1 会返回一个被公钥 PUK1 加密过的 K1。按照推论,结果就是只有 D1 能够解密。
K1P1D1 = enc(K1, PUK1)
P1 使用它的本地 DRM 系统(这可以使用 SoC ,一个专门的硬件和软件,这个系统可以使用它的私钥 PRK1 用来解密内容,它可以解密被加密过的K1P1D1 的对称密钥 K1。理想情况下,密钥不会被导出到内存以外的地方。
K1 = dec(K1P1D1, PRK1) P1.play(dec(C'1, K1))
现代互联网的发展历程经历了文字–声音/图片–视频这么几个阶段,从最开始人们之间发消息、打电话起,过渡到可以互相发送图片,再到现在网络视频和直播的兴起,人与人之间的距离不断地被拉近,交流也更加方便、直观。由于工作中主要涉及到视频方面的相关知识,因此对视频的编解码进行一点简单的研究,是很有必要的。
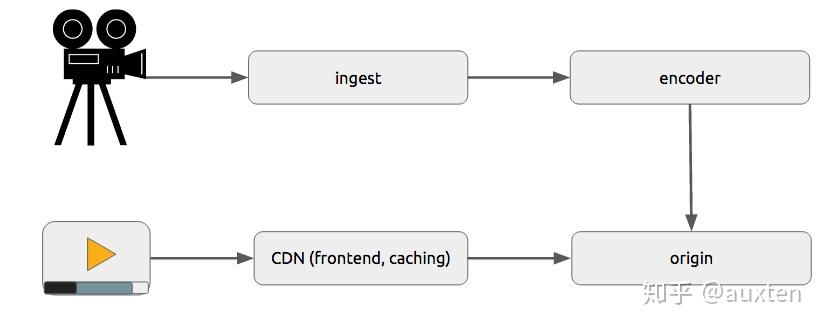
流媒体技术的基本过程
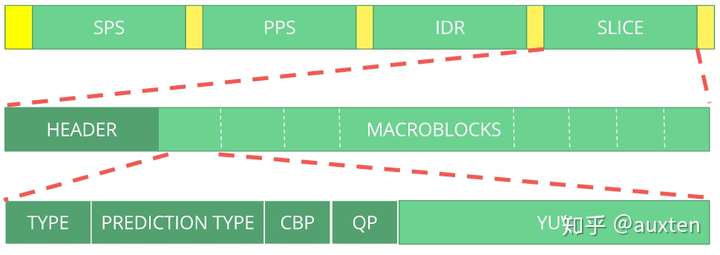
总体上说,视频从产生到传递到观看者之间的过程主要分为这么几个阶段:录制—编码—传输—解码—播放
-
录制:即视频的制作者利用各种摄像设备,将现实中的一些连续的场景片段记录下来。
-
编码:对录制好的视频进行格式化处理,以方便在网络上传输。主要有对视频和音频分别进行压缩编码、将音视频进行打包封装两个步骤。
-
传输:将视频上传到源站服务器上,然后用户端再从服务器上拉取视频。有时为了系统的稳定性和用户体验,需要再中间添加CDN节点,由CDN节点去源站服务器上拉取,用户再根据某个规则去对应的CDN服务器上进行拉流。
-
解码:是编码的逆过程,需要对从网络上获取的数据进行解协议,得到该视频的封装包,再解包,分别得到经过编码的音频和视频数据,最后再将这些音视频数据按照对应的编码格式进行解码。
-
播放:也称作渲染的过程。对解码出来的音频和视频进行同步,而后就可以在播放器端进行播放了。
研究的重点在于编解码上,由于解码是编码的逆过程,所以在此只画出解码过程图,具体如图所示:
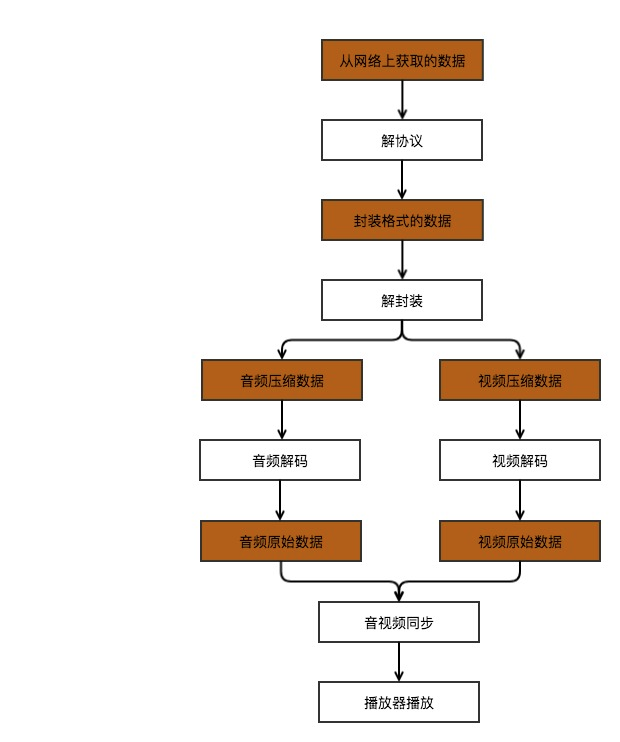
图片参考自雷霄骅的博客
多媒体的格式分类
封装格式
封装格式就是将视频压缩数据和音频压缩数据打包起来,以特定的方式将他们合并成一个文件。所以总体上各种封装格式之间并没有太大的不同。不过也有优劣之分,有的封装格式几乎支持所有的音视频编码,而有的只支持很少的音视频编码。常见的封装格式有以下几种:
-
AVI(Audio Video Interleave):只能封装一条视频轨和音频轨,不能封装文字,没有任何控制功能,因而也就无法实现流媒体,其文件扩展名是.avi。
-
WMV(Windows Media Video):具有数字版权保护功能,其文件扩展名是.wmv/.asf。
-
MPEG(Moving Picture Experts Group):可以支持多个视频、音轨、字幕等,控制功能丰富,其文件扩展名是.mp4。
-
Matroxska:提供非常好的交互功能,比MPEG更强大,其文件扩展名是.mkv。
-
QuickTime File Farmat:由Apple开发,可存储内容丰富,支持视频、音频、图片、文字等,其文件扩展名是.mov。
-
FLV(Flash Video):由Adobe Flash延伸而来的一种视频技术,主要用于网站。
-
Real Video:只能容纳Real Video和Real Audio编码格式的媒体,其文件扩展名是.rmvb。
封装格式不影响视频的画质,它只负责把视频轨和音频轨集成在一起,只起到一个文件夹(或者压缩包)的作用,并没有对视频轨或音频轨造成影响。
视频编码格式
视频编码主要是为了将视频像素数据压缩成视频码流,以降低视频的大小,从而方便网络传输和存储。常见的有:
-
H.264
-
MPEG-4
-
MPEG-2
-
VP8
-
VP9
-
VC-1
音频编码格式
和视频一样,音频编码也是为了将音频原始数据转换为音频码流,以便在网络传输。常见的有:
-
AAC
-
AC-3
-
MP3
-
WMA
流媒体协议
-
RTP
-
RTCP
-
RTSP
-
RTMP
-
HLS
H264
H264视频压缩算法是现在所有视频压缩技术中使用最广泛。
H264压缩技术主要采用了以下几种方法对视频数据进行压缩。包括:
-
帧内预测压缩,解决的是空域数据冗余问题。
-
帧间预测压缩(运动估计与补偿),解决的是时域数据冗徐问题。
-
整数离散余弦变换(DCT),将空间上的相关性变为频域上无关的数据然后进行量化。
-
CABAC压缩。
经过压缩后的帧分为:I帧,P帧和B帧:
-
I帧:关键帧,采用帧内压缩技术。
-
P帧:向前参考帧,在压缩时,只参考前面已经处理的帧。采用帧音压缩技术。
-
B帧:双向参考帧,在压缩时,它即参考前而的帧,又参考它后面的帧。采用帧间压缩技术。
除了I/P/B帧外,还有图像序列GOP。
-
GOP:两个I帧之间是一个图像序列,在一个图像序列中只有一个I帧。如下图所示:
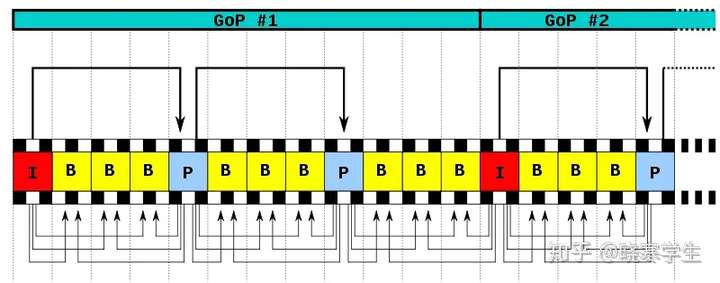
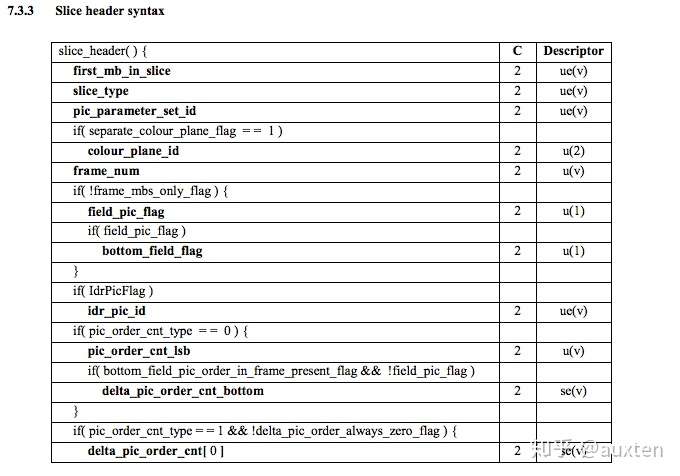
SPS 、PPS
SPS 、PPS是用来描述GOF(一组帧),在一组帧之前,我们会先收到SPS 、PPS。没有这两个参数是无法解码的。
SPS (序列参数集 Sequence Parameter Set)
包含一组帧中:存放帧数、参考帧数目、解码图像尺寸、帧场编码模式选择标识等
PPS ( 图像参数集 Picture Parameter Set)
包含一组帧中:存放熵编码选择模式标识、片组数目、初始量化参数和去方块过滤波系数调整标识等。
视频出现花屏、卡顿的原因
-
丢帧造成花屏
当一组帧中丢失了某一帧,就会造成某个部分没有完成更新。造成花屏。 -
丢GOP造成卡顿
为了避免花屏的问题,当发现I帧或P帧丢失,则不现实本GOP中所有的内容。知道下一个I帧到达后重新刷新图像。
视频编解码器
-
x264/x265
x264是目前使用最广泛的H264编解码器(主要用来编码,解码用ffmpeg)。 x265的压缩率比x264更高,性能的消耗也更大。
-
openH264
相对x264性能较低,但支持SVC技术。
SVC可以将视频分层传输:
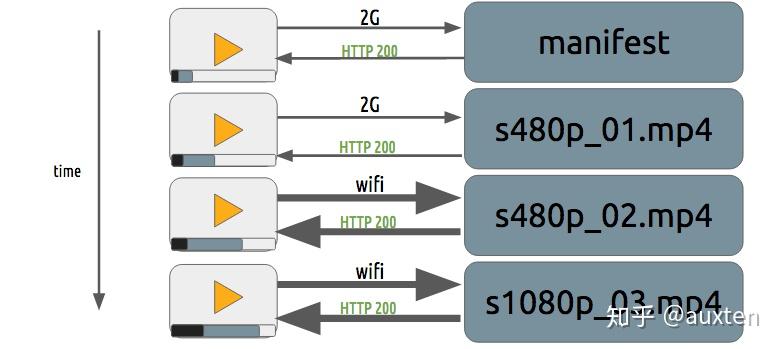
可以对用户带宽进行不同策略的定制方案:将一帧数据分为小、中、大三个部分,根据对方网络情况分别追加发送。
接收到的部分越多,最后组合起来的视频就越清晰。 但由于很多手机不支持SVC编码,所以需要使用软编处理,会对CPU产生损耗。
-
vp8/vp9
Google出品,分别对应x264/x265
相关:
视频编解码的过去、现在和未来 https://zhuanlan.zhihu.com/p/28969271